Data Insights Platform
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| ongoing |
ankitbhatnagar
|
ahegyi
|
dennis
nicholasklick
lfarina8
|
group platform insights | 2025-04-10 |
Summary
Data Insights Platform is a unified abstraction to ingest, process, persist & query analytical data streams generated across GitLab enabling our ability to compute business insights across the product.
The motivation behind building a centralized data platform manifests from our work within the Product Usage Data Unification Working Group wherein we established a need for consolidating all our current multiple ways of collecting analytical & product usage data generated across GitLab into a single cohesive abstraction with a few key goals:
- Stitch together multiple pieces of analytics-specific functionality into one cohesive product feature backed by a single abstraction/system.
- Build the ability to ingest all analytical data into a centralized, scalable unit of processing & querying such data without compromising ease of use for stakeholders.
Motivation
-
Build within the product
- A core design tenet with the Platform is to build it within the product - with zero external dependencies and deep-integration with GitLab/GDK similar to existing services such as Gitaly.
- Ensure the availability of the Platform across all environments we run a GitLab instance in -
.com, Dedicated and Self-managed. The design of the Platform should also allow deploying cluster-instances for Cells as applicable.
-
Streamlined user experience
- Abstract away undue complexity from a Platform user or developer. The Platform should perform its advertised features without the end-user having to reinvent the wheel every time they need to gather analytical data and/or be able to query/process it once collected.
-
Feature consolidation
- Consolidate any analytics-related events-emitting system/feature under the same logical abstraction minimising the work developers need to do to add new functionality.
-
Production-ready
- Ensure the Platform is secure, scalable, reliable & maintainable for the foreseeable future.
-
Future-proof implementation
- Ensure the Platform is sufficiently modularised to allow changing its dependencies.
- Ensure all ingested data can be routed to multiple systems across our technology stack depending on the needs of the product.
Goals
-
Consolidate the various event-collection mechanisms and simplify supporting infrastructure and/or systems - inline with our decisions in the following Architecture Design Records (ADRs) from the working group:
-
The existence of a centralized data platform helps enable the following key outcomes with the full data lifecycle in mind:
- Unified data collection and storage.
- Efficient data movement across systems.
- Secure data access and governance.
- Data visualization and exploration.
Our latest update on Data Unification and Insights presents these in further details.
- Broadly speaking, the Platform should enable a paved path for us to build an event-driven platform within the product.
Proposal
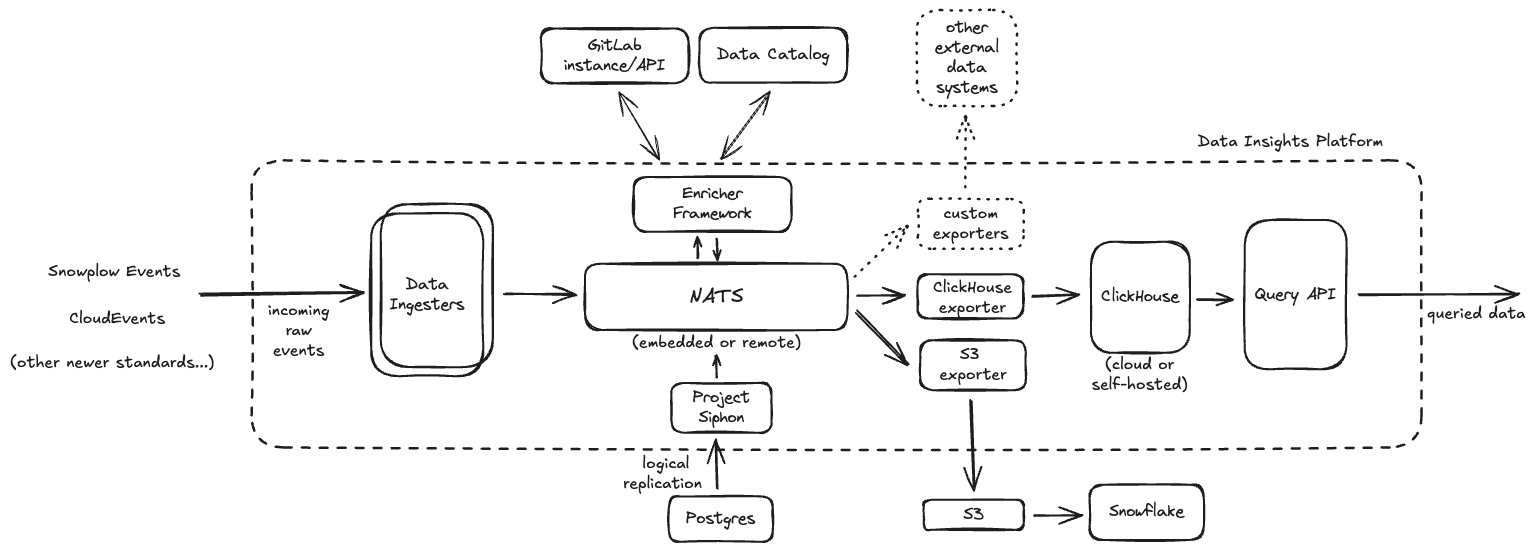
Data Insights Platform is a logical abstraction comprising a set of components functioning together to structurally form a scalable data-pipeline that allow us to ingest, process and persist large volumes of analytical data into designated datastores from where it can be queried efficiently.
Following is a brief description of each underlying component. Note, we have also compiled architecture blueprints for some of these individually to ensure we can deep-dive into further details of each component and gather valuable feedback from a wider audience.
-
Ingester(s): Single ingestion mechanism for supported event types - which can be run both locally for development & as a cluster when in production. This layer is intentionally stateless to allow horizontal scalability to allow ingesting large data volumes. We aim to build the support for ingesting the following event-types:
- Snowplow (current iteration)
- CloudEvents (next iteration)
- Service Ping (future iteration)
-
Siphon: Custom, in-house Change Data Capture (CDC) implementation to logically replicate data from Postgres into other systems such as ClickHouse.
-
NATS: Embedded/Distributed system to buffer incoming data prior to processing/enriching.
-
Enrichment Framework: Custom framework to enrich incoming data with the ability to communicate with external components such as GitLab API or Data Catalog for metadata.
- Supported enrichments include operations such as pseudonymization or redaction of sensitive parts of ingested data, PII detection, parsing client useragent strings, etc.
-
Exporters: Custom implementations that help ship ingested data into designated persistent stores for further querying/processing.
- ClickHouse Exporter: ClickHouse is our designated persistent database which helps us persist all analytical data ingested by the Platform and query from using the
Query API. - S3/GCS Exporter: Having data shipped to
S3/GCShelps land data into Snowflake powering our current analytical query-workflows using Snowflake & Tableau.
- ClickHouse Exporter: ClickHouse is our designated persistent database which helps us persist all analytical data ingested by the Platform and query from using the
-
ClickHouse: External persistent database that allows for durable persistence and advanced OLAP querying capabilities for all analytical data ingested within the Platform.
-
Query API: Custom, semantic querying layer for clients/UIs to query data persisted within ClickHouse.
Identified use-cases
Following is a detailed set of use-cases that benefit from the existence of a centralized data platform within the product.
| Teams/areas | Use-cases | Expected scale |
|---|---|---|
| Enterprise Data/Infrastructure | Logically replicating data out of Postgres. | ~100GB of new data ingested from Postgres per hour. We’ll also need to scale with Cells architecture. |
| Platform Insights | Ingesting & processing large amounts of analytics data in real-time, then persisting it into ClickHouse. | Product Usage Data: 1200 events/sec (100M daily), ~15GB/hour, expected to increase with increase in instrumentation + 2.5x when pursuing event-level data collection from the customer’s domain (about 300M events daily). |
| Machine Learning | Extracting & processing events/features from GitLab data to create training/test datasets for ML models at scale. | |
| Security & Compliance | Extracting and actioning upon events, e.g., audit events, from GitLab data in near real-time. | Audit events saved to database per day (excludes streaming only audit events) - ~0.6M records are created per day (audit event coverage has stalled due to load on Postgres, this is likely to increase if this migrates over to an event pipeline) Streaming only audit events generated per day (this excludes audit events saved to DB) - ~35M streaming only events are created per day. Total estimates would be at ~40M events per day. See Kibana dashboard (internal). |
| Product | Generic Events Platform to asynchronously process data, events & tasks. Ingesting & processing external data via webhooks as a service. | |
| Product | Implementing real-time analytics features on top of ClickHouse. | Data volume: Similar or less than what we observe with the PostgreSQL databases. Depends on how many tables we replicate (Siphon) to ClickHouse. Enqueued event count: significantly lower as we’re batching the CDC events into packages. |
| Plan | JIRA Compete Strategy | |
| Optimize | Ingesting JIRA data | |
| Fulfillment | Consumption Billing for Dedicated Hosted Runners |
Deployments
With the intention to make the Data Insights Platform available to every GitLab installation, we aim to build necessary support for the following deployment models:
| Deployment type | Proposed topology |
|---|---|
| GDK | Running local to the installation |
.com |
One or more dedicated cluster(s) |
| Cells | One or more clusters subject to cells-topology |
| Dedicated | One dedicated cluster per instance |
| Self-Managed | Standalone cluster subject to distribution/instance-sizing |
Rollout roadmap
| Deliverables | Timeline | Description |
|---|---|---|
| Pre-staging/Testing | FY26Q1 | Deployed to GKE using this project. |
.com Staging |
TBD | - |
.com Production |
TBD | - |
| Gradual rollout to Dedicated | TBD | - |
| Gradual rollout to Self-managed | TBD | - |
Opportunities looking forward
- Sharing analytical data externally, including with our customers wherein any ingested or enriched data and insights derived from it can be shared with all stakeholders as permissible within our SAFE framework.
- Ability to generate insights & metrics around business continuity faster.
- Building flexible/loose coupling between analytical parts of the product, allowing components to be switched should our future business needs change.
- Scalable data ingestion pipeline for augmenting our AI initiatives across GitLab, for example, help power RAG ingestion pipelines.
- Gathering operational insights from running software systems at GitLab, existing proposal at Proposal: GitLab Observability Component - Structured Events.
Design & Implementation
Monolithic implementation
- The Platform must be developed within a single project using Go.
- The Platform must be developed and packaged as a single binary allowing it to run standalone and be well-integrated with GDK for local development.
- The Platform must also support running in a distributed fashion - scaling out as multi-service deployments when needed. The implementation should allow for it to be broken down into multiple services by using flags wherein each service can run independently on their own compute pools for independent scalability.
NATS + JetStream as a centralised data buffer
- Considering NATS can both be embedded within an application and scale out as a cluster when needed, NATS makes it trivial for us to deploy NATS clusters across all our reference architectures we decide to run the Platform in.
- With NATS forming the data backbone of the Platform, it makes it trivial for us to:
- Be able to ingest data from multiple event-sources,
- Be able to centrally & dynamically process & enrich it without having to send data across systems,
- Be able to route it to other data-related systems as needed.
Minimal external dependencies
- With the only direct storage dependency being ClickHouse, it should be possible to develop & test all analytical features within the Platform completely locally within GDK.
Support for common standards
- Snowplow for structured/tracked events via a consolidated event instrumentation layer.
- CloudEvents for custom structured events.
Looking forward, we should also be able to assimilate other currently used formats such as Service Ping or remodel them with one of aforementioned supported common standards.
Architecture
As suggested in the diagram above, the Platform is essentially a composition of multiple components functioning together to resemble a scalable data pipeline capable of ingesting, processing and persisting data durably in one or more persistent datastores. From the diagram, data ingestion starts at the ingesters which pushes it into one or more NATS streams - subject to configured partitioning and/or data retention policies. In a following step, the enricher framework dequeues data as necessary, performs all configured enrichments and writes it back to one or more designated NATS streams. Following this, configured exporters pick up enriched data from NATS and ship it to one or more downstream datastores. This is where any necessary fan-out of data happens - moving all enriched data from a single source into systems where that data might be needed. All data querying can now happen from these datastores and/or systems.
Having NATS available in-between the producers and consumers of these data streams helps decouple the two - allowing them to scale independently of each other, considering data volumes at ingress can be much higher than what we can process and/or persist durably. This architecture also accounts for handling any backpressure within the pipeline without affecting the health of involved components. We intend for all data ingestion to be highly performant while downstream processing or exporting of data happens asynchronously in a more regulated fashion subject to downstream systems and/or their operational capacity.
Security
The following sections describe how we ensure the Platform and the data ingested or queried from it remains secured.
Authentication & Authorization
- All internal communication in between GitLab (monolith) and the Platform must be encrypted using TLS.
- For Platform’s data ingestion and querying endpoints, we intend to defer most authentication & authorization decisions onto GitLab (monolith) itself. When ingesting data, all events will be forwarded to the endpoint by using the
event forwarderimplementation within the Rails application. When querying data, all requests will also be pre-authorized by the monolith and the corresponding service(s) within GitLab will use a shared-token to talk to the Platform (similar toGitaly). - Platform’s internal interactions with NATS will be authenticated and authorized as necessary.
- Platform’s internal interaction with ClickHouse will be authenticated and authorized as necessary.
Encryption
- Data while at rest within NATS will remain encrypted by using filesystem encryption.
- Data persisted durably in ClickHouse will also remain encrypted. For ClickHouse Cloud, we can start with Transparent Data Encryption (TDE) or Customer Managed Encryption Keys (CMEK) as applicable.
Auditing & Logging
- For the environments we manage, logs from all Platform components must be shipped to centralised logging as applicable.
Operations
- The
single-binaryimplementation allows scaling out each component of the Platform individually. When needed, each of ingester, enricher & exporter can be scaled and run on a segregated node-pool. - Internally, we aim to shard incoming data across N distinct
NATS streamswhich can then be consumed by multiple instances of the enricher/exporter processes.
Scalability
- On our testing instance, we ran the following configuration:
"--replicas=5",
"--streams=5",
"--enricher-workers=10",
"--flush-batch-size=1000",
"--flush-interval-seconds=10",
for the single-binary running a 5-replica statefulset (2 vCPU, 2GB memory each) on a GKE cluster with each node of the type c2d-standard-16 and were able to ingest, enrich and persist Snowplow events within ClickHouse at about 6000 events per second on ingress and ~1600 events per second landed on ClickHouse.
-
Drawing from our experience with running the current Snowplow infrastructure for GitLab, we intend our first iteration of the Platform to scale & handle upto 500 million events per day with upto 1 million events per minute at peak. From an infrastructure footprint standpoint, we intend for our current traffic volumes to be handled with reasonably lesser resources than we employ right now.
-
Siphon has also been confirmed to be replicating logical replication events at ~5700 events per second with Postgres being our current bottleneck. More details of Siphon’s performance testing is available in this issue. We also tested failing over the underlying NATS cluster during these tests and the complete dataset recovered successfully as soon as NATS service was back functional.
-
A single cluster is the top-level deployment unit of the Platform, as described in the architecture diagram above. If needed, we can deploy one or more clusters of the Platform to accommodate for scale and/or tenant-isolation per cluster. For example, when ingesting data from Self-managed or Dedicated GitLab instances, it can be routed to different Platform clusters to ensure one’s traffic volumes does not interfere with the resources of another.
Monitoring
- For components developed internally, we must add sufficient instrumentation and expose telemetry as Prometheus metrics.
- For the environments we manage, metrics from all Platform components must be shipped to our internal monitoring backends (Mimir) as applicable and added to our internal dashboards.
970b0def)
