Development Escalation Process
Quick escalation guide
Please use/devoncall <incident_url> on Slack for any escalation that meets the criteria.
Note
We use Pagerslack for weekday escalations. Weekend escalations rely on the spreadsheet solely.About This Page
This page outlines the development team on-call process and guidelines for developing the rotation schedule for handling incident escalations.
Expectation
The expectation for the development engineers is to be a technical consultant and collaborate with the teams who requested on-call escalation to troubleshoot together. There is no expectation that the development engineer is solely responsible for a resolution of the escalation.
Escalation Process
Scope of Process
- This process is designed for the following issues:
- GitLab.com and self-managed hosting
operational emergenciesraised by the Infrastructure , Security, and Support teams. - Engineering emergencies raised by teams in engineering such as the Delivery and QE teams, where an imminent deployment or release is blocked.
- Engineering emergencies raised by teams in product such as the Product Operations team, where the imminent deployment of the Release Post is blocked.
- Engineering emergencies raised by teams in quality such as the Engineering Productivity team, where merge requests merges are blocked due to the
masterbranch failing.
- GitLab.com and self-managed hosting
- This process is NOT a path to reach development team for non-urgent issues that the Infrastructure, Security, and Support teams run into. Such issues can be moved forward by:
- Labelling with
securityand the@gitlab-com/security/appsecteam mentioned to be notified as part of the Application Security Triage rotation - Labelling with
infradevwhich will be raised to Infra/Dev triage board - Raising to the respective product stage/group Slack channel, or
- Asking the #is-this-known Slack channel
- Labelling with
- This process provides 24x7 coverage.
Example of qualified issue
- Production issue examples:
- GitLab.com: DB failover and degraded GitLab.com performance
- GitLab.com: Severity 1 vulnerability being actively exploited or high likelihood of being exploited and puts the confidentiality, availability, and/or integrity of customer data in jeopardy.
- Self-managed: Customer ticket - Our GitLab instance is down - request an emergency support
- Self-managed: Customer ticket - Database overloaded due to Sidekiq stuck jobs
- Engineering emergency examples:
- A post deployment issue with version.gitlab.com that will cause self-managed deployment failure.
- GitLab.com deployment or a security release is blocked due to pipeline failure.
- A severity::1 regression found in the release staging.gitlab.com
- Evaluating severity and making decision on a potential release or deployment show stopper collaboratively when other engineering teams are challenged to accomplish alone.
masterpipelines are broken.
Examples of non-qualified issues
- Production issue examples:
- GitLab.Com:Errors when import from GitHub
- GitLab.com: Last minute security patch to be included in an upcoming release
- Self-managed(ZD): View switch causing browser freeze
- Self-managed(ZD): Watch Everything Notification Level
- Engineering issue examples:
Process Outline
NOTE: On-call engineer do not need to announce the beginning and end of their shift in #dev-escalation unless there is an active incident happening (check the chat history of the channel to know if there is an active incident). This is because many engineers have very noisy notifications enabled for that channel, and such announcements are essentially false positives which make them check the channel unnecessarily.
Weekdays (UTC)
Weekdays will now leverage an automated system relying upon the Pagerslack.
- Incidents will be escalated by Pagerslack and randomly select a Backend Engineer (BE) that is currently online in Slack and eligible due to their working hours.
- Pagerslack would also factor recency into the algorithm so that BEs that had recently been involved in an incident would be selected last.
- During incidents a randomly selected BE has the option to pass the incident to another BE if they are urgently needed somewhere else.
- Engineers who are eligible to be on-call during weekend shifts are deprioritized from the process
Escalation
- SRE et al, types
/devoncall incident-issue-urlinto #dev-escalation - Pagerslack randomly selects a Backend Engineer (BE) first responder based on: working hours, whether they are online and notifies them via slack/cell etc.
- BE responds to the Pagerslack thread with 👀
- If Primary does not respond a secondary will be notified.
- Pagerslack will continue trying up to 6 different BEs with a preference for those who do not take weekend shifts
- BE triages the issue and works towards a solution.
- If necessary, BE reach out to domain experts as needed.
In the event that no BE engineers respond to the bot, Pagerslack will then notify the Engineering Managers. They will need to find someone available and notify this in the escalation thread. As an EM:
- Check whether some of the engineers pinged belong to your group and see whether they are available to help
- Try to find someone available from your group
- If the search is positive, leave a message in the thread as an acknowledgement that the engineer from your group will be looking into the issue
Weekends and Holidays (UTC)
Weekends/Holidays are included in the On-call spreadsheet. Those holidays include: Family & Friends days, and any major holidays that affect multiple timezones.
There are restrictions of eligibility in certain localities, which can be found in the weekend column of the Development Team BE spreadsheet spreadsheet. This spreadsheet is refreshed by the end of each month automactically via the Employment Automation.
Escalation
- SRE et al, types
/devoncall incident-issue-urlinto #dev-escalation - Pagerslack posts a link to the On-call spreadsheet
- SRE contacts the scheduled BE via Slack or make a phone call 5 minutes after Slack ping. Refer to bullet 3 under #process-outline.
- BE triages the issue and works towards a solution.
- If necessary, BE will reach out to domain experts as needed.
Reaching out to domain experts
NOTE: these people generally do not carry pagers and are only likely available during business times. Please respect the individual intake processes, this helps each team track their work.
Use the product sections handbook page to determine whom to contact.
- Get attention from Gitaly team: issues related to Git and Git repositories, Gitaly Cluster, including data recovery.
- Get attention from Fulfillment team: issues related to CustomersDot (customers.gitlab.com).
First response time SLOs
OPERATIONAL EMERGENCY ISSUES ONLY
- GitLab.com: Development engineers provide initial response (not solution) in both #dev-escalation and the tracking issue within 15 minutes.
- Self-managed: Development engineers provide initial response (not solution) in both #dev-escalation and the tracking issue on a best-effort basis. (SLO will be determined at a later time.)
- In the case of a tie between GitLab.com and self-managed issues, GitLab.com issue takes priority.
- In the case of a tie between production (GitLab.com, self-managed) and engineering issues, production issue takes priority. The preferred action is to either backout or rollback to the point before the offending MR.
Required Slack Channel and Notification Settings
- All on-call engineers, managers, distinguished engineers, fellows (who are not co-founders) and directors are required to join #dev-escalation.
- On-call engineers are required to add a phone number that they can be reached on during their on-call schedule to the On-call spreadsheet.
- On-call engineers are required to turn on Slack notification during regular working hours. Please refer to Notification Settings for details.
- Similarly, managers and directors of on duty engineers are also recommended to do the same above to be informed. When necessary, managers and directors will assist to find domain experts.
- Hint: turn on Slack email notification while on duty to double ensure things don’t fall into cracks.
Rotation Scheduling
Important: Sign-ups of weekends/holidays are required as a backup while using Pagerslack as the primary escalation tool.
Guidelines
Assignments
On-call work comes in four-hour blocks, aligned to UTC:
- 0000 - 0359
- 0400 - 0759
- 0800 - 1159
- 1200 - 1559
- 1600 - 1959
- 2000 - 2359
One engineer must be on-call at all times on weekends and company holidays. This means that each year, we must allocate 756 4-hour shifts.
The total number of shifts is divided among the eligible engineers. This is the minimum number of shifts any one engineer is expected to do. As of February 2024 we have around 206 eligible engineers, this means each engineer is expected to do 4 shifts per year, or 1 shift per quarter.
In general, engineers are free to choose which shifts they take across the year. They are free to choose shifts that are convenient for them, and to arrange shifts in blocks if they prefer. A few conditions apply:
- No engineer should be on call for more than 3 shifts in a row (12 hours), with 1-2 being the norm
- No engineer should take more than 12 shifts (48 hours) per week, with 10 shifts (40 hours) being the usual maximum.
Scheduling and claiming specific shifts is done on the On-call spreadsheet.
Scheduling spreadsheets
The following internal-only scheduling spreadsheets are maintained as part of the development team on-call process:
- On-call spreadsheet
- Development Team BE spreadsheet
- IMOC Rotation emails spreadsheet
- Excluded Team Member Emails
- Summit Availability
Eligibility
All backend and fullstack engineers within Core Development, Expansion Development, or Core Platform who have been with the company for at least 3 months, with exceptions recorded in the Excluded Team Member Emails spreadsheet.
Other general exceptions: (i.e. exempted from on-call duty)
- Distinguished engineers and above.
- Intern and Associate engineers.
- Where the law or regulation of the country/region poses restrictions. According to legal department -
- There are countries with laws governing hours that can be worked.
- This would not be an issue in the U.S.
- At this point we would only be looking into countries where 1) we have legal entities, as those team members are employees or 2) countries where team members are hired as employees through one of our PEO providers. For everyone else, team members are contracted as independent contractors so general employment law would not apply.
- Team members participating in another on-call rotation.
The eligibility is maintained in this Development Team BE spreadsheet and part of the spreadsheet is refreshed automatically by our automation script.
Nomination
Engineers should claim shifts themselves on the On-call spreadsheet. To ensure we get 100% coverage, the schedule is fixed one month in advance. Engineers claim shifts between two and three months in advance. When signing up, fill the cell with your full name as it appears in the team members list (internal only), GitLab display name, and phone number with country code. This same instruction is posted on the header of schedule spreadsheet too.
At the middle of each month, engineering managers look at the schedule for the following month (e.g. on the 15st March, they would be considering the schedule for April, and engineers are claiming slots in May). If any gaps or uncovered shifts are identified, the EMs will assign those shifts to engineers. The assignment should take into account:
- How many on-call hours an engineer has done (i.e., how many of their allocated hours are left)
- Upcoming leave
- Any other extenuating factors
- Respecting an assumed 40-hour working week
- Respecting an assumed 8-hour working day
- Respecting the timezones engineers are based in
- Ensuring assigned on-call shifts fit between the hours of 8am-8pm local time for all team members in general, and 7am-9pm for engineers in the US Pacific Time timezone (approved in this issue).
- Optimize for better alignment of shift hours
- When assigning the first Friday shifts (00:00 UTC/Saturday 1pm NZT/ 4-6pm PST). Please favour/allocate these shifts to AMER engineers within their working hours.
- When assigning the final Sunday shift of a typical weekend 20:00-00:00 UTC/Sunday Monday NZT, choose a New Zealand based engineer unless it is a public holiday in New Zealand.
In general, engineers who aren’t signing up to cover on-call shifts will be the ones who end up being assigned shifts that nobody else wants to cover, so it’s best to sign up for shifts early!
There is additional information regarding weekend shifts, which can be found in “Additional Notes for Weekend Shifts”(internal only) under a sub-folder called Development Escalation Process in the shared Engineering folder on Google Drive.
Relay Handover
-
Since the engineers who are on call may change frequently, responsibility for being available rests with them. Missing an on-call shift is a serious matter.
-
In the instance of an ongoing escalation, no engineer should finish their on-call duties until they have paged and confirmed the engineer taking over from them is present, or they have notified someone who is able to arrange a replacement. They do not have to find a replacement themselves, but they need confirmation from someone that a replacement will be found.
If the shift for the current on-call dev is ending, and the incoming on-call dev listed in the On-call spreadsheet is not responding, please use the following process to find an engineer to take over the shift, stopping the process as soon as an engineer is found:
-
Call the phone number for the incoming on-call dev listed in the On-call spreadsheet to see if they’re able to fulfill their assigned shift.
-
Get in touch with the next on-call dev listed in the On-call spreadsheet, if it’s within their working hours, to see if they’re able to take on both their assigned shift, as well as the shift from the unavailable incoming on-call dev.
-
Post a message to the existing incident thread in the #dev-escalation channel, or create a new thread requesting volunteers to take over the shift.
-
Message the on-call IMOC and ask them for help finding an engineer to take over the shift.
-
-
In the instance of an ongoing escalation being handed over to another incoming on-call engineer the current on-call engineers summarize full context of on-going issues, such as but not limited to
-
Current status
-
What was attempted
-
What to explore next if any clue
-
Anything that helps bring the next on-call engineer up to speed quickly
These summary items should be in written format in the following locations:
- Existing threads in #dev-escalation
- Incident tracking issues
This shall be completed at the end of shifts to hand over smoothly.
-
-
For current Infrastructure issues and status, refer to Infra/Dev Triage board.
-
For current Production incident issues and status, refer to Production Incidents board.
-
If an incident is ongoing at the time of handover, outgoing engineers may prefer to remain on-call for another shift. This is acceptable as long as the incoming engineer agrees, and the outgoing engineer is on their first or second shift.
-
If you were involved in an incident which has been mitigated during your shift, leave a note about your involvement in the incident issue and link to it in the #dev-escalation Slack channel indicating you participated in the issue as an informational hand-off to future on-call engineers.
Development on-call DRI
Current DRI: James Lopez
The development on-call DRI has the following responsibilities:
- Ensure the process and this handbook page is up to date and promptly fix any problems or answer any queries
- Select coordinators for the monthly schedule (at least 15 days before the new month starts) - a tool can be used to assist with this
- Keep the IMOC Rotation emails spreadsheet up to date and export them monthly from Pagerduty.
- Keep the Excluded Team Member Emails spreadsheet up to date.
- Keep the On-call spreadsheet up to date, including Family and Friends days, other general public holidays,
Total Shift counts, and escalation tracking - Keep the Summit Availability spreadsheet up to date.
- Monitor
#dev-escalationand#dev-oncallon Slack and resolve any problems with the escalation bot and the PeopleOps integration - Track, document, and keep up to date eligibility criteria as well as onboarding/offboarding and remind Engineering managers about this process
- Implement an appreciation process for engineers who were on-call and handled recent incidents
Coordinator
Given the complexity of administration overhead, one engineering director or manager will be responsible to coordinate the scheduling of one month. The nomination follows the same approach where self-nomination is preferred. If there are no volunteers, the DRI will select them for upcoming months.
The coordinators should assign themselves to the corresponding monthly issue from this epic.
Responsibility
The coordinator will:
- Remind engineers to sign up, by:
- Posting reminders to the #development and #backend channels in Slack
- Asking managers in #eng-managers to remind team-members in 1-1s
- Assign folks to unfilled slots when needed. Use purple text in the spreadsheet to indicate this was an assigned slot.
- Ensure that all developers listed in the On-call spreadsheet have:
- Provided a phone number
- Confirmed their shift by changing the font color of their entry from purple to black.
- Coordinate temporary changes or special requests that cannot be resolved by engineers themselves. Fix any schedules that conflict with local labor law.
- After assigning unfilled slots and accommodating special requests the coordinator should click Sync to Calendar > Schedule shifts.
This will schedule shifts on the
On-call schedule shiftscalendar and if any developer added their email into the spreadsheet, they will be added as guests in the on-call calendar event. Ensure that you have subscribed to the calendar before syncing.
An Epic of execution tracking was created, where each coordinator is expected to register an issue under this Epic for the month-on-duty to capture activities and send notifications. Here is an example.
How-To
Refer to this coordinator issue template for instructions or the steps below. The same template is used for monthly on-call planning and execution issues.
An automated process can be followed. If there are problems with the tool, a manual process can be followed:
- Start by finding the least filled shift (Usually this is 00:00 - 04:00 UTC) in the On-call spreadsheet.
- Determine the appropriate timezone for this shift (in the case of 00:00 - 04:00 it is +9,+10,+11,+12,+13).
- Go to the Development Team BE spreadsheet and filter the “timezone” column by the desired timezones for the shift. Now you have the list of possible people that can take this shift. Alternatively, you can use this dev-on-call tool to find out people who may take this shift.
- Go to google calendar and start to create a dummy event that is on the day and time of the unclaimed shift . NOTE you will not actually end up creating this event.
- Add all of the people that can possibly take the shift to the event as guests.
- Go to the “Find a Time” tab in the calendar event to see availabilities of people.
- Find a person that is available (preferring people that have taken less than 4 shifts per quarter and few or no shifts overall, based on the shifts counts sheet (internal only)). Note people who are on leave or otherwise busy or in interviews, do not schedule them for the shift. It would be fine to ignore events that appeared to be normal team meetings, 1:1, coffee chat as people can always leave a meeting if there is an urgent escalation.
- Assign them to the shift by filling their name in the On-call spreadsheet in Purple font color.
- Now since there are likely many days that have this unfilled time slot then update the event date to the next day with this same unfilled time zone. Since it’s the same time then the same set of people will be appropriate to take the shift which means you don’t need to update the guest list.
- Repeat all of the above for all of the unclaimed timezones remembering that you want to solve for one shift (by time range) at a time as it means you will re-use the same guest list to determine availability.
Additional Notes for Weekend Shifts
For those eligible engineers, everyone is encouraged to explore options that work best for their personal situations in lieu of weekend shifts. When on-call you have the following possibilities:
- Swap weekend days and weekdays.
- Swap hours between weekend days and weekdays.
- Take up to double the time off for any time worked during the weekend when the above two options don’t work with your personal schedule.
- When an engineer is in standby mode (e.g. not paged) during the weekend shift, they can take 1.25x time-off.
- When an engineer is in call-back mode (e.g. being paged) during the weekend shift, they can take double the time-off.
- For those who reside in Australia, please refer to these guidelines of time in lieu in the handbook.
- Please create an OOO event in Workday and choose On-Call Time in Lieu.
- Other alternatives that promote work-life balance and have the least impact to your personal schedule.
It is important to abide by local labor laws and you are encouraged to understand if there are restrictions around your working time. The purpose of this information is to encourage you to take time off according to your schedule to account for the interruption to your weekend.
If you prefer to work on a preferred weekend day please proactively sign up for shifts to avoid auto-assignment. Team members who have signed up for the fewest shifts are auto-assigned open shifts first.
Rotation Schedule
See the On-call spreadsheet.
Resources
Responding Guidelines
Infrastructure or availability incident
When responding to an Infrastructure Incident, utilize the below procedure as guidelines to follow to assist both yourself and the members requesting your assistance
- Respond to the slack page with the
:eyes:reaction - this signals to the bot that you are looking into the problem - Join the appropriate incident slack channel for all communications that are text based - Normally this is
#inc-<NUMBER> - Join the Incident Zoom - this can be found bookmarked in the relevant incident Slack Channel
- Work with the EOC to determine if a known code path is problematic
- Should the knowledge of this be in your domain, continue working with the Engineer to troubleshoot the problem
- Should this be something you may be unfamiliar with, attempt to determine code ownership by team - Knowing this will enable us to see if we can bring online an Engineer from that team into the Incident
- Work with the Incident Manager to ensure that the Incident issue is assigned to the appropriate Engineering Manager - if applicable
Master broken guidelines
You can read about the process workflow here and follow the triage responsibilities
Bot (Pagerslack) Usage
- In order to use the bot, type
/devon-call incident-issue-urlto trigger the escalation process. - Message the bot privately with
topto show the top 25 members that are next in the escalation queue - Message the bot privately with
positionto see your position in the queue. The higher the number, the less probabilities to get pinged.
Please report any problems by creating an issue in the pagerslack project.
Shadowing An Incident Triage Session
Feel free to participate in any incident triaging call if you would like to have a few rehearsals of how it usually works. Simply watch out for active incidents in #incidents-dotcom and join the Situation Room Zoom call (link can be found in the channel) for synchronous troubleshooting. There is a nice blog post about the shadowing experience.
Replaying Previous Incidents
Situation Room recordings from previous incidents are available in internal Google Drive folder.
Shadowing A Whole Shift
To get an idea of what’s expected of an on-call engineer and how often incidents occur it can be helpful to shadow another shift. To do this simply identify a time-slot that you’d like to shadow in the On-call spreadsheet and contact the primary to let them know you’ll be shadowing. Ask them to invite you to the calendar event for this slot. During the shift keep an eye on #dev-escalation for incidents and observe how the primary follows the process if any arise.
Tips & Tricks of Troubleshooting
- How to Investigate a 500 error using Sentry and Kibana.
- Walkthrough of GitLab.com’s SLO Framework.
- Scalability documentation.
- Use Grafana and Kibana to look at PostgreSQL data to find the root cause.
- Ues Grafana and Prometheus to troubleshoot API slowdown.
- Related incident: 2019-11-27 Increased latency on API fleet.
- Let’s make 500s more fun
Tools for Engineers
- Training videos of available tools
- Dashboards examples, more are available via the dropdown at upper-left corner of any dashboard below
Help with the process
If you have questions about the process, please reach out to #dev-oncall in Slack or to the DRI directly.
Pagerslack statistics
Notification Settings
To make the First Responder process effective, the engineer on-call must configure their notifications to give them the best chance of noticing and responding to an incident.
These are the recommended settings. Your mileage may vary.
Slack Notifications
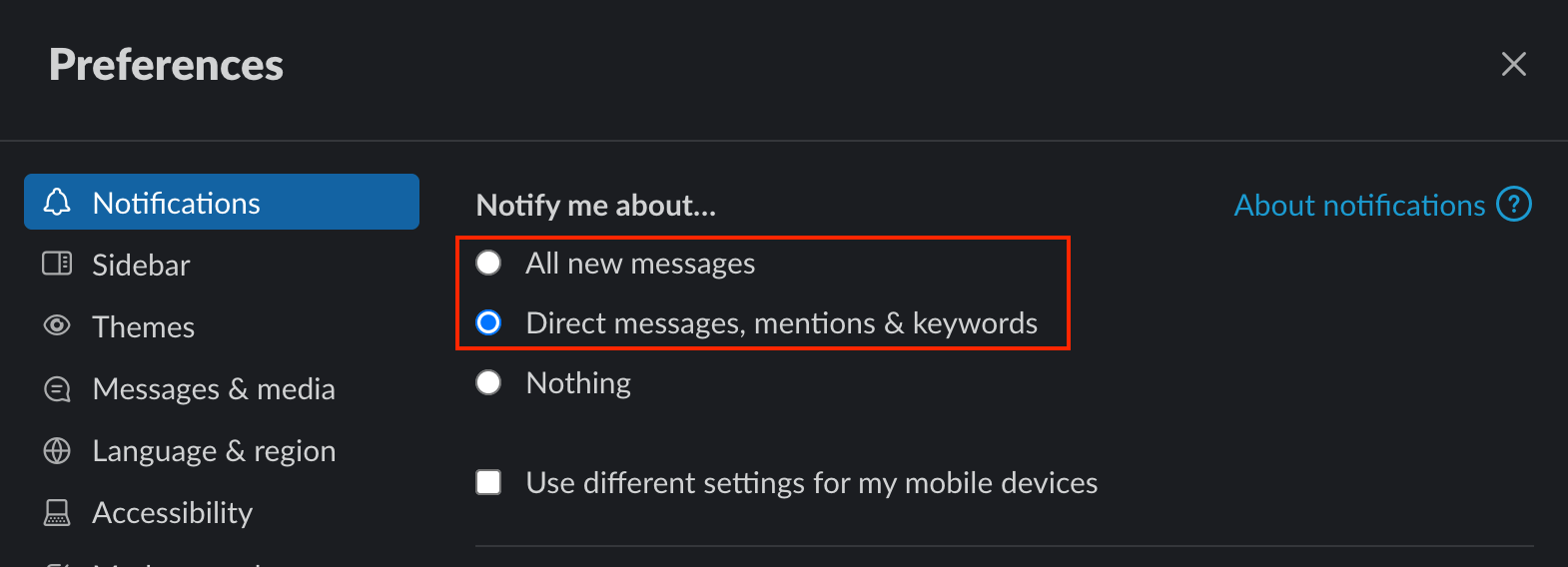
- Within Slack, open “Preferences”.
- Under “Notify me about…”, select one of the first two options; we recommend “Direct messages, mentions & keywords”. Do not choose “Nothing”.
- If you check “Use different settings for my mobile devices”, follow the same rule above.
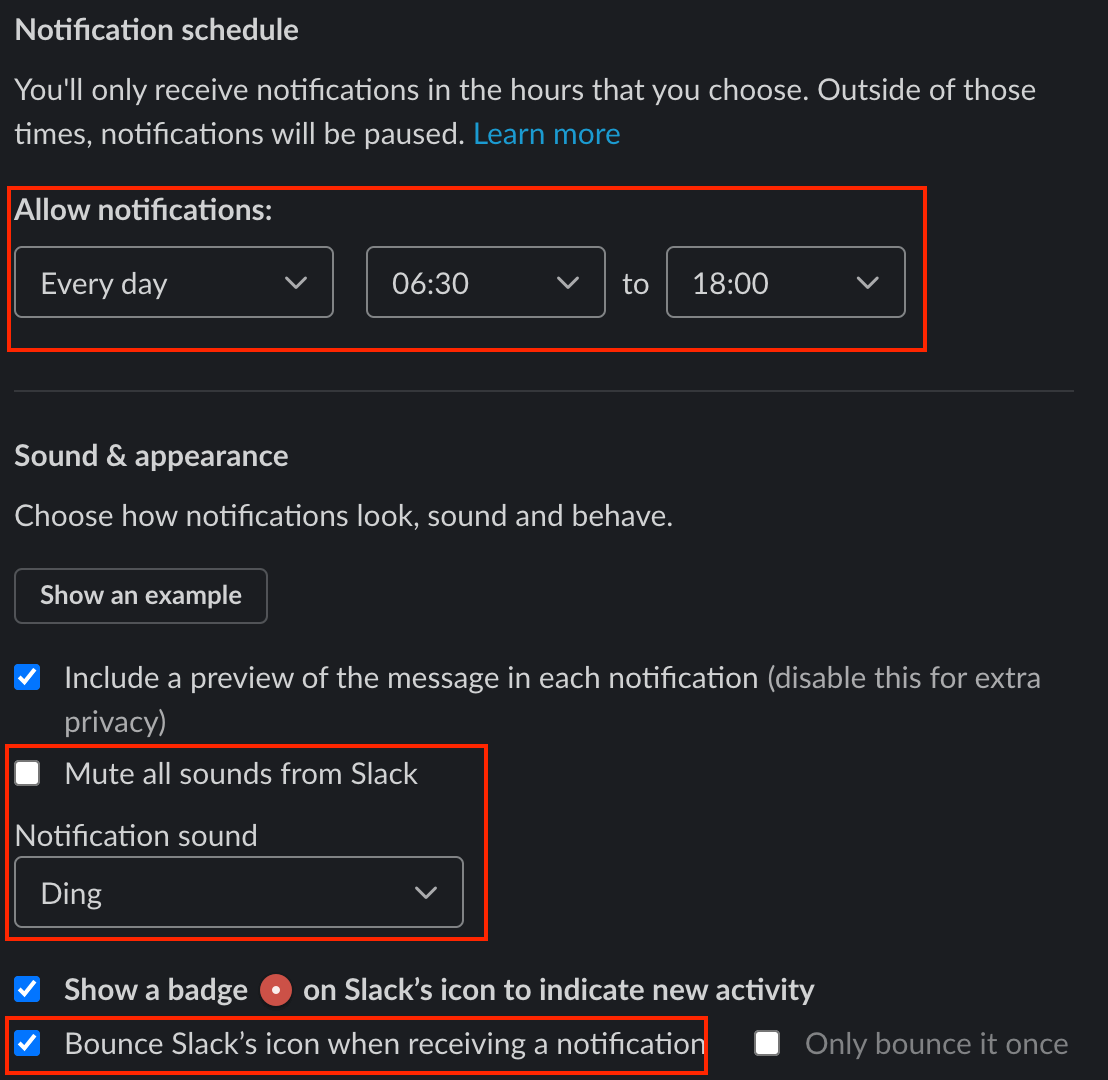
- Scroll down to “Notification Schedule”.
- Under “Allow notifications”, enter your work schedule. For example: Weekdays, 9 am to 5 pm. Pagerslack relies on this to decide whether or not to page a person.
- Scroll down to “Sound & appearance”.
- Choose settings that ensure you won’t miss messages. We recommend:
- Select a “Notification sound”.
- Check “Bounce Slack’s icon when receiving a notification”.
- Use your preference for the other settings. The “Channel-specific notifications” are particularly helpful to mute noisy channels that you don’t need to be interrupted for.
macOS Notifications
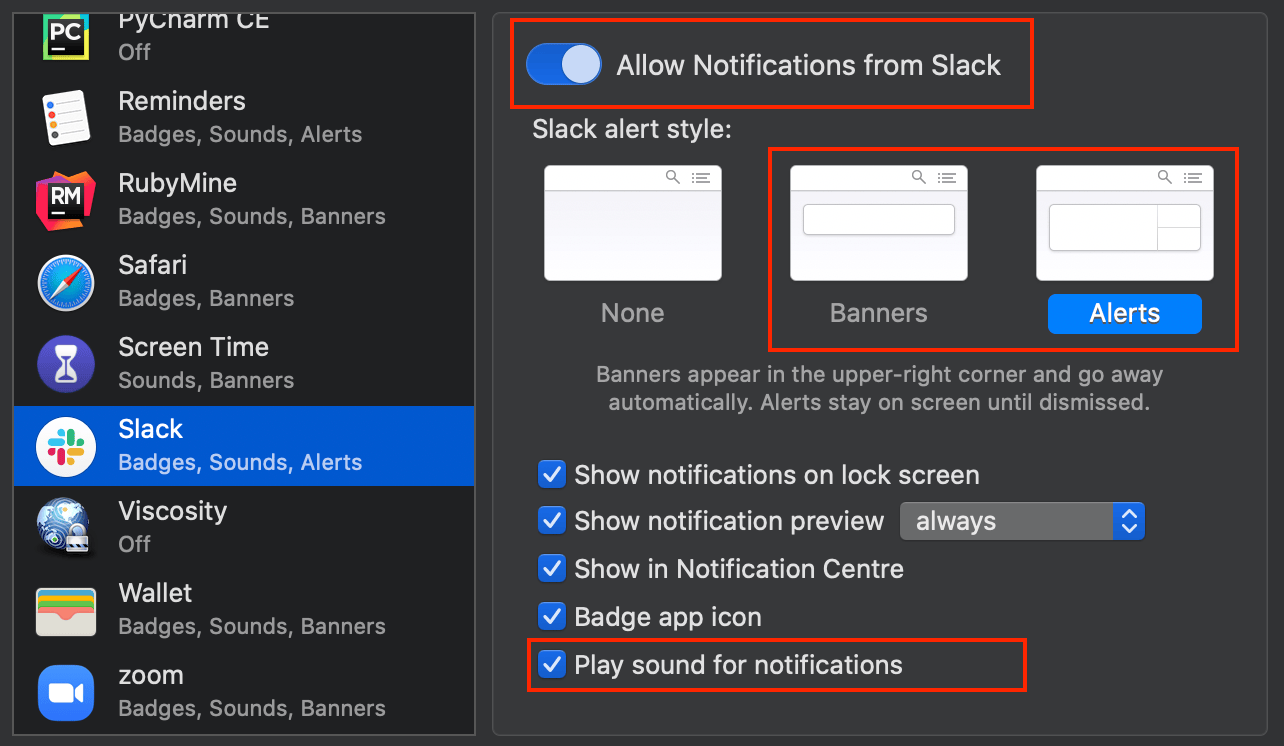
- Under “System Preferences”, select “Notifications”.
- Scroll down to find “Slack”.
- Enable “Allow Notifications from Slack”.
- For “Slack alert style”, we recommend “Alerts” so you need to dismiss them. “Banners” might also work for you. Do not select “None”.
- Enable “Play sound for notifications”, particularly if you chose “Banners” above.
- Use your preference for the other settings.
iOS Notifications
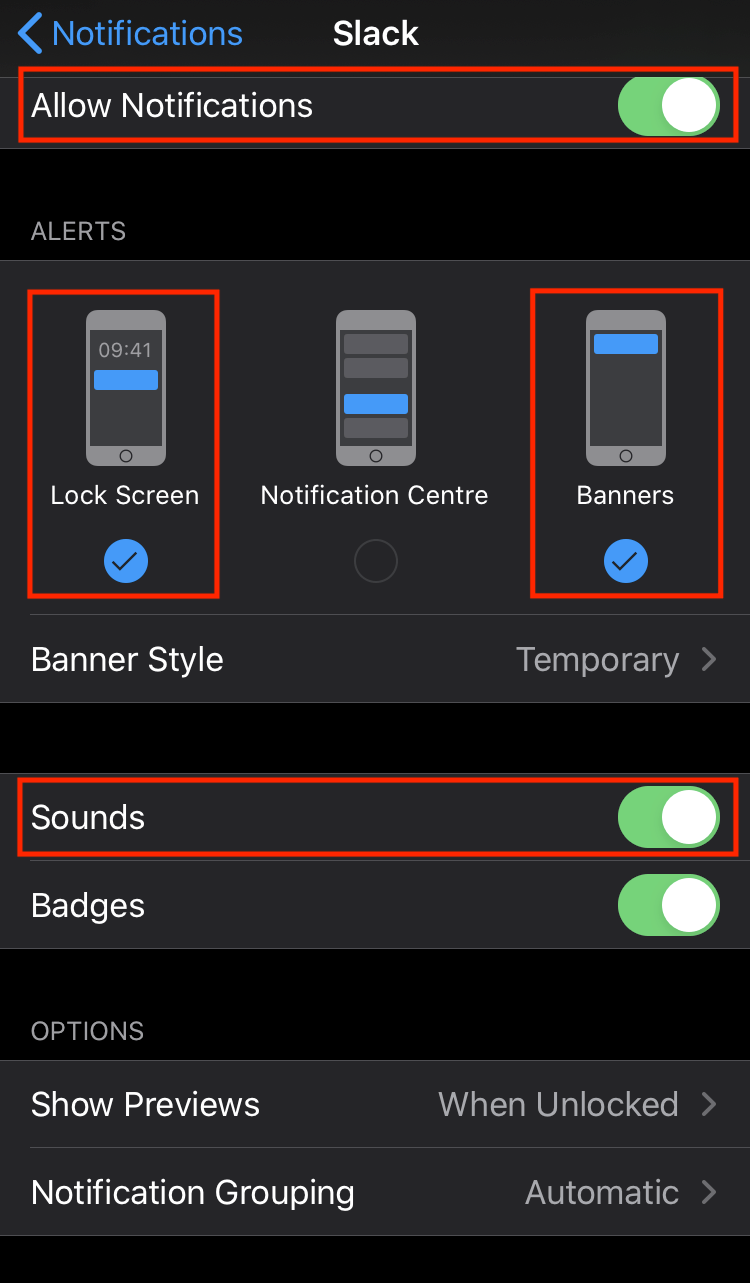
- Under “Settings”, open “Notifications”.
- Scroll down to find “Slack”.
- Enable “Allow Notifications from Slack”.
- Under “ALERTS”, enable “Lock Screen” and “Banners”.
- Enable “Sounds”.
- Use your preference for the other settings.
390fb6ca)
