Advanced Global Search Rollout on GitLab.com
Steps and Enhancements 2019-11-05: Search security rapid action started.
Advanced Global Search went …
The Global Search Group focuses on bringing world class search functionality to GitLab.com and self-managed instances.
This page covers processes and information specific to the Global Search group. See also the Global Search and Code Search direction pages.
The group is responsible for improving and expanding upon our current global search implementations using Elasticsearch, PostgreSQL, Zoekt, and Gitaly. Areas of responsibility will include global search functionality, UI, ingestion mechanisms, optimal indexing, administrative tools, and installation mechanisms for self-managed installations.
Additionally, we build and maintain critical AI context infrastructure, including:
These systems will be fundamental to providing high-quality context for AI features via Retrieval Augmented Generation work, which includes:
This team doesn’t own custom searches for specific features, such as the “filter bar” on issues which is part of the Issue Tracking category owned by the Project Management group.
The following team members are permanent members of the Global Search Group:
| Name | Role |
|---|---|
 Changzheng Liu Changzheng Liu
|
Backend Engineering Manager, Global Search |
The following members of other functional teams are our stable counterparts:
| Name | Role |
|---|---|
| Ashraf Khamis | Senior Technical Writer |
| Cleveland Bledsoe Jr | Senior Support Engineer |
| Brenda Nyaringita | Support Engineer(EMEA) |
The Global Search team shares responsibilities with the AI Framework team in the area of  (RAG). Specifically, we will collaborate in the data preparation stage and information retrieval stage of the RAG process.
(RAG). Specifically, we will collaborate in the data preparation stage and information retrieval stage of the RAG process.
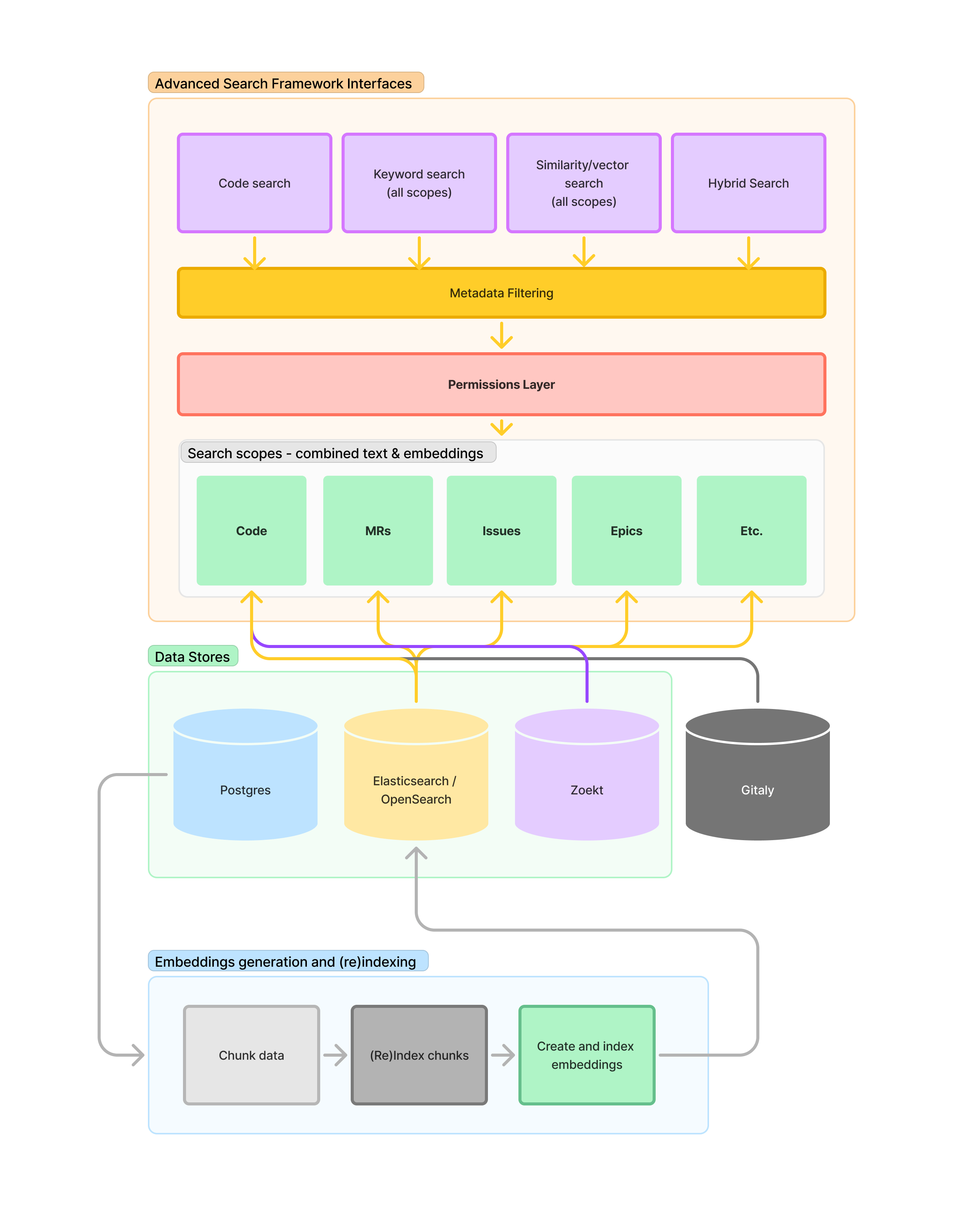
The Global Search team maintains several key systems that power both traditional search and AI context capabilities:
These systems work together to provide comprehensive search and AI context capabilities, from traditional keyword search to sophisticated vector similarity matching for AI features.
Beyond powering GitLab’s global search functionality, Advanced Search serves as a critical framework that enables other teams across GitLab to overcome the inherent limitations of PostgreSQL for complex search and analytics use cases. Teams leverage Advanced Search infrastructure to:
This framework approach allows feature teams to focus on their domain expertise while leveraging battle-tested, scalable search infrastructure maintained by the Global Search team.
Basic search utilizes Postgres for text searching and Gitaly for code searching. Both functionalities are significantly limited compared to with Advanced search.
There are many data types and search scopes already available via the Advanced Search interfaces. Below is a table that outlines the various available data types and the status of various functional elements, such as permissions, cross-group searching, and embeddings.
| Data type / scope | Privacy / Permissions | Cross-namespace / cross-group searching | Keyword search | Similarity search & Embeddings | Metadata filtering |
|---|---|---|---|---|---|
| Code | Yes | Yes | Yes | In progress | Group, Project, Include/exclude archived, include/exclude forks, Language, Filename, Path, Extension |
| Issues | Yes | Yes | Yes | Yes | Group, Project, Status, Confidentiality, Labels, Include/exclude archived |
| Merge requests | Yes | Yes | Yes | No | Group, Project, Status, Include/exclude archived |
| Epics | Yes | Yes | Yes | No | Group, Project |
| Comments | Yes | Yes | Yes | No | Group, Project, Include/exclude archived |
| Users | Yes | Yes | Yes | No | Group, Project |
| Commits | Yes | Yes | Yes | No | Include/exclude archived |
| Milestones | Yes | Yes | Yes | No | Group, Project, Include/exclude archived |
| Project | Yes | Yes | Yes | No | Group |
| Wiki | Yes | Yes | Yes | No | Group, Project |
Whenever possible, we prefer to communicate asynchronously using issues, merge requests, and Slack. However, face-to-face meetings are useful for establishing a personal connection and addressing items that would be more efficiently discussed synchronously, such as blockers.
We follow the general workflow and principles defined in Product Development Flow and Engineering Workflow. To bring an issue to our attention, please create an issue in the relevant project. Add the ~"group::global search" label and any other suitable labels. If it is an urgent issue, please reach out to the Product Manager or Engineering Manager listed in the Stable Counterparts section above.
Below are a few guidelines the team follows in the day-to-day work.
workflow::problem validation and workflow::solution validation for user research and workflow::design for UI design and prototyping. Once the design is finished, workflow::ready for development label will be added as an indicator that development can start. For minor UX/UI changes, we contact our UX counterpart or the Product Design Manager to request a review for fast iterations.documentation and adding our counterpart in the Technical Writing team as assignee. Our technical writer helps us update the corresponding document. The documentation change normally happens together with the code change.Before a major milestone starts, we prepare an epic with all the breaking change issues linked. As usual, we work to get approvals but keep the MR in draft to prevent it from merging before the major milestone. If an MR is independent, we can have the master as a target branch. If not, we can have a sequence of MRs with target branches set to each other. As soon as the first one merges, the next will automatically target master.
Every MR that was created before the breaking change milestone should have this or a similar warning in the description: :warning: This MR must be kept as a draft and cannot be merged until **DATE** :warning:
We review the bugfix merge requests every week. To facilitate this process, we have created scoped labels: backport::required, backport::skip, and backport::complete.
backport::skip label will be added to merge requests if no backport is needed.backport::required label will be added to the merge requests that need to be backported to a previous release in the initial review. The DRI will follow the patch release process to backport the fix to a previous release. Once the backport is done, the backport::complete label will be added to indicate the whole process is complete.The team has been actively working on enabling Elasticsearch powered Advanced Search on GitLab.com. Based on our analysis, we set our first target to roll this feature out for all the paid groups on GitLab.com. You can find more details about the timeline and progress in the links below.
~advanced search, ~global search)| Type of Operation | ~severity::1 - Blocker |
~severity::2 - Critical |
~severity::3 - Major |
~severity::4 - Low |
|---|---|---|---|---|
| Recall Record, Global | Above 10 seconds to timing out | Between 7 and 10 seconds | Between 4 and 7 seconds | Between 2 and 4 seconds |
| Time until inserted record is recallable | Above 15 minutes | Between 15 and 10 minutes | Between 10 and 5 minutes | Between 3 and 5 minutes |
The two types of operations we detail severity metrics for above are:
We use the Fibonacci rating system to assign weights to Search issues. Below are a few guidelines when setting issue weight:
~backend and ~frontend work should have the weights added for a total weight representative of the work effort.~backend and ~frontend work.| Weight | Description |
|---|---|
| 0 | No effort or trivial effort (example: Documentation typo or Feature Flag Rollout) |
| 1 | Low effort (No Database migrations or Advanced Search migrations) |
| 2 | Low-Medium effort |
| 3 | Medium effort |
| 5 | High effort |
We have the following guidelines for doing reviews on Global Search Team MRs:
As the Global Search Team requires special domain knowledge, such as Elasticsearch, we borrow team members with this domain knowledge from other groups to cover the on-call escalation when we are understaffing, especially during the holiday seasons. In general, we will follow the Tier 2 On-Call Program for escalations requiring domain expertise. The Elasticsearch domain experts, identified by domain_expertise on their profile, may be contacted when SRE and Tier 2 on-call engineers cannot resolve the production incidents. We don’t expect the domain experts to work outside their normal working hours. In case of emergency, we will follow the rules and best practices outlined in our Incident Management handbook. To assist team members in catching up on the latest development status and resolving potential incidents, we have created a Global Search Incident Management document as a reference.
When onboarding domain experts from other groups to help cover production incident escalation, we may consider the following actions:
elasticsearch as their domain_expertise in their team member profileWe utilize the Jobs to be Done (JTBD) framework to better understand our customers’ and users’ needs. You can view the current list of our JTBD here.
We are exploring Rally for performance testing the Elasticsearch cluster. Workload data is determined using Kibana and stored in a Google Sheet (internal)
