GitLab Translation Service
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| proposed |
rasamhossain
|
username
|
product-manager
engineering-manager
|
2024-11-08 |
Summary
This design document outlines the architectural design for an automated translation tool and a pipeline that provides translations for GitLab repositories and Translation Management Systems (TMS) used by Translation Vendors using a middleware Localization Request Management system called Argo. The integration tool is designed to automatically monitor and process translation requests for specified content changes in GitLab repositories through an event-driven Java application.
The objective of this design document is, however, not entirely on the application itself, but rather how we deploy this application in our GitLab infrastructure. But both of them will be discussed throughout the document.
The integration tool (which is a java application) implements an asynchronous, queue-based processing system that handles high-volume events from multiple projects/repositories while maintaining data consistency and preventing race conditions. It orchestrates the entire translation workflow - from detecting file changes in specific folders of interest, routing content through Argo’s request management pipeline, all the way to managing the commit of translated content back to GitLab repositories.
The tool will be deployed in GitLab infrastructure:
- The application code is hosted through a GitLab repository under Localization group, and builts the image file using GitLab’s CI/CD pipeline
- The relevant database is hosted through Google Cloud,
- And deployed using Runway and connects to the GCP CloudSQL instance using PSC (Private Service Connect) and Cloud SQL Auth Proxy.
Motivation
The development of this automated localization pipeline addresses several critical challenges:
- Manual overhead reduction:
- Previously, all localization processes required manual intervention, creating a significant bottleneck,
- Project managers were spending excessive time coordinating between development teams and translation vendors,
- High risk of human error in file handling and version management.
- Operational efficiency:
- Automates the complete workflow from source string detection to translation deployment,
- Eliminates the need for manual file transfers between systems,
- Significantly reduces the time from source string updates to localized content availability.
- Scalability benefits:
- Capable of handling increasing volumes of translation requests without additional resource allocation,
- Supports multiple repositories and projects simultaneously,
- Easily adaptable to new language requirements and vendor integrations.
- Quality assurance:
- Maintains consistent file structure and naming conventions,
- Ensures version control integrity through automated commit processes,
- Reduces the risk of missing translations or outdated content.
- Cost effectiveness:
- Reduces operational costs associated with manual localization management,
- Minimizes project delays and resource allocation issues,
- Optimizes translation vendor utilization through streamlined request management.
This automated pipeline represents a significant step forward in modernizing the localization workflow, ensuring both efficiency and accuracy in managing multilingual content across GitLab repositories.
Goals
Current Goals
Simplify and automate GitLab’s translation pipeline with its translation vendors:
- Introduces an end-to-end automated localization infrastructure and pipelines - translating strings located in a GitLab repository,
- No manual human intervention required - engineers, PMs, and other associate stakeholders would save hours managing translations between GitLab and translation vendors,
- Ensuring higher accuracy in file handling and organizing large projects and decrease time-to-market for localized content,
Future Goals
- Ability to create translation requests from within Argo by selecting the files manually, and then automate to run on a schedule.
- Create a robust error handling and automated quality checks for file formats.
- Set up automated QA checks for common localization issues.
- Establish monitoring for translation consistency and set up automated testing procedures.
Proposal
It’s important to emphasize that while this document touches on the tool’s features and it’s core functionality will be briefly discussed to provide context, the primary focus is on the deployment architecture and infrastructure implementation within our GitLab environment. This approach ensures a clear understanding of how the tool and the translation pipeline fits into and operates within our broader infrastructure ecosystem.
The proposal is divided into two sections. Section 1: outlines the overall architectural flow and operational mechanics of the translation pipeline within the tool itself. Section 2: details the deployment architecture, infrastructure requirements, and implementation strategy for the proposed solution.
Section 1 : The Tool
- Continuous monitoring and tracking: The integration tool monitors GitLab repositories and detects closed Merge Request(s) on that repositories.
- Source file identification: If there’s a change in the source en-US folder as a part of a merged MR, the tool identifies it and extracts the content from the GitLab API.
- Translation request: Once extracted, it automatically creates an Argo Request for identified files requiring translation.
- Vendor pipeline: Argo orchestrates translation workflow through configured vendor integrations based on GitLab’s localization specifications.
- Translated file integration to GitLab: Once the translation is complete and available to Argo, it automatically commits translated files back to GitLab.
- Verification, review & merge: A Localization Engineer reviews the Argo’s commit containing translated files, approves, and merges back to the repository.
Section 2: Deployment architecture
- The integration tool is located in a GitLab repository, and get’s build into a docker file container using GitLab’s CI/CD pipeline.
- Once that’s done, the docker container will be deployed with Runway.
- Since Runway doesn’t support PostGresSQL as of now, we’ll connect to a database server on Google Cloud.
Section 3: Target repositories
As of now, this tool is intended only to use with few public projects under tech-docs and marketing. Here’s the complete list:
For Marketing
| Repository Link | Repository Content | Branch Specifications |
|---|---|---|
| about-gitlab-com | Contents | using a translation branch |
For Tech-docs
We’ll be initially using a fork of the tech-docs repos, which includes all the test and prod repos located here : https://gitlab.com/gitlab-com/localization/tech-docs-forked-projects
In near future, once approved, we’ll move to using a translation branch. Here’s the list of all the repositories:
Section 4: Database Configuration
It should be noted here that the database will never contain any sensitive data. No secrets, tokens or api keys will be stored in the database. We’ll be using a separate GitLab account with limited access to the target repositories.
Data saved in Database
- Entire webhook body contents, which contains all sorts of metadata related to the GitLab MR and the repo it resides in. You can see all the datahere.
- When the webhooks were recieved and processed, along with their status regarding their processing,
- MRs identifiers and their relation to each other (what Translation MRs are tied to which Original MRs)
Possible future updates to the Database
- We will likely expand the tool for a cadence based translation instead where the application doing a periodic check and not relying on events - thus expanding on the number of events stored,
- Currently an engineer verifies the MRs before merging them to the target repository. If we add features on the tool to likely expand on merge automation, we may likely include more logging information to troubleshoot success/failures.
Note: Any data stored in the database in Phase 1 (see below) will be deleted from Spartan’s environment, once the infrastructure moves to Phase 2 (see below) under GitLab.
Design and implementation details
Spartan Software, Inc. (“Spartan”) has helped us building a Java application that act as the intermediary tool to communicate with the Request Management System - Argo.
In summary, here’s what the tool does:
- The integration tool continuously monitors certain GitLab projects or repositories,
- Anytime a Merge Request is closed on the monitored project, the integration tool receives the Merge Request data from GitLab API - that gets extracted to identify the list of en-US source language files,
- The tool then creates an Argo Request for these files that requires translation,
- Argo manages the translation on its end with the translation vendors assigned by GitLab,
- Whenever translation has completed on file(s) associated in the Request, Argo attempts to commit the file(s) back to GitLab.
- An engineer reviews the commits of the Merge Request created by Argo, approves them, and get the files merged to the repository.
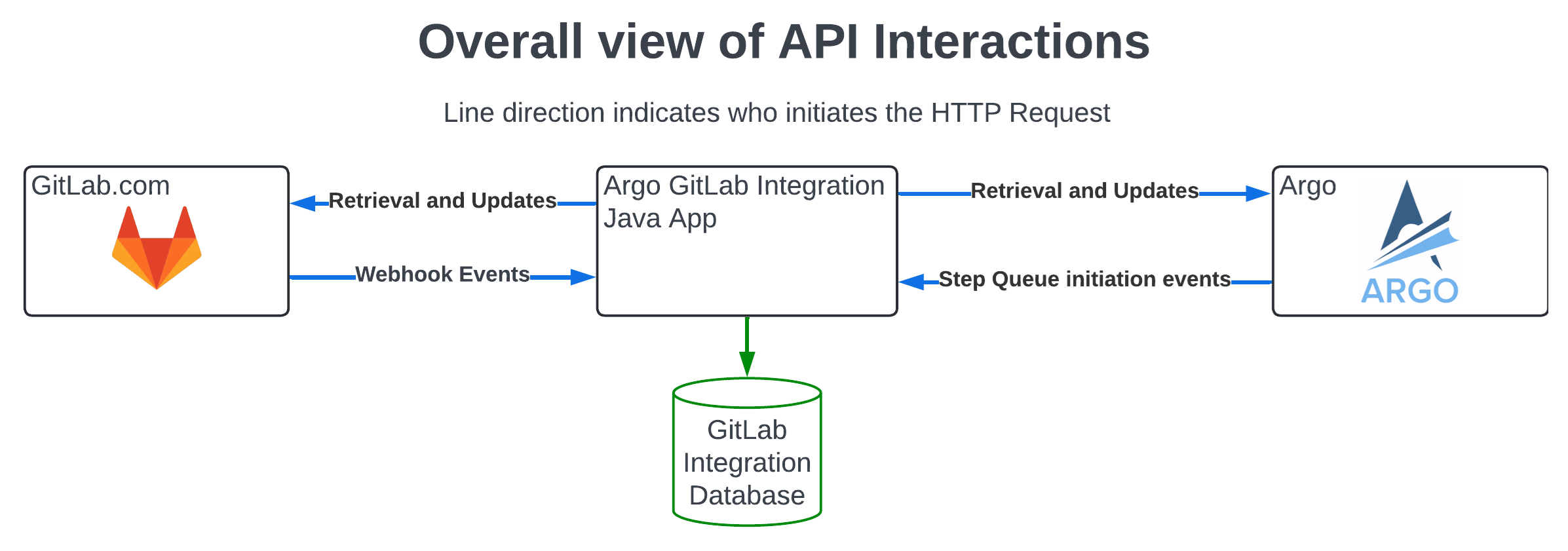 Overall view of the API interactions
Overall view of the API interactions
And the scope of actions
- Read contents of repository, including every branch and MRs
- Create new branches and add new commits to existing branches that it creates
- Create new commits
- Create MRs from that repository to itself or to other repositories
As we’ve noted earlier, separate GitLab account with limited access will be associated with this tool only. A user token will be created with the following permissions only with limited expiration dates:
- api
- read_repository
- write_repository
How do we authenticate the user?
For the GitLab’s webhooks, we use access tokens for this user to authenticate.
For Argo, the integration is protected by hosting them on the same instance or within a firewall, thereby preventing outside access. In addition to this there’s currently work-in-progress of implementing authentication Argo<->GitLab integrations. This will require enhancing Argo to also use a token when communicating with the GitLab Integration, and also the GitLab Integration being enhanced to use said token.
Lifecycle of an event
The application is event driven. The application remains dormant until either GitLab or Argo send in an HTTP Request to the application. The application will then handle the event and perform, sometimes quite complex, operations.
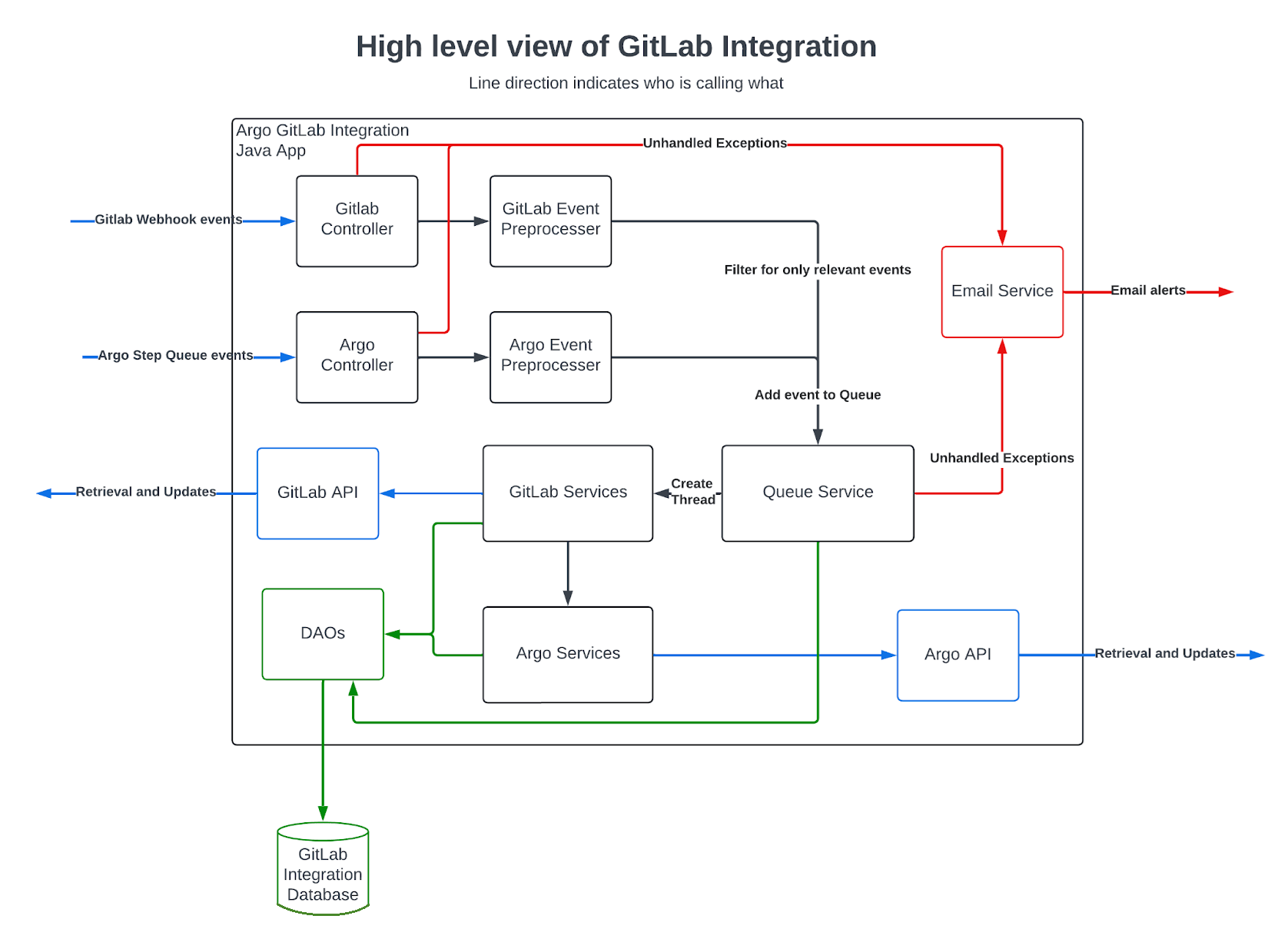 High Level Architecture
High Level Architecture
Event preprocessing
Quick checks and handling for large volumes of HTTP Requests before putting them into the queue.
- Argo or GitLab events are received to
ArgoControllerorGitLabControllerrespectively, auth is checked, then passed unaltered to the next service.- Purpose: Simple endpoint that allows the internal services to be interfaced with, and authenticate the request
- More on
ArgoController: receives events from Argo. When the source language files have completed translation and are ready in Argo, Argo will make a call to the GitLab Integration informing what has completed, which it receives via theArgoController. From there, the GitLab Integration will grab the translated file, create a branch and MR if necessary, and the commit to that branch.
- (GitLab Event)
GitLabWebhookServicewill take the event, convert that data, and check if it’s relevant. If the checks find it is relevant, then it’s added to the queue- Purpose: Filter out most of the junk events, convert the data into a more manageable form, handle events immediately, prevent the queue and database being filled with useless events
- (Argo Event)
ArgoStepServicewill take the event and just add it to the queue- Purpose: All Argo events are relevant so this has no use, but if in the future we need to do preprocessing like with the GitLab events, then this serves as a convenient place to do so
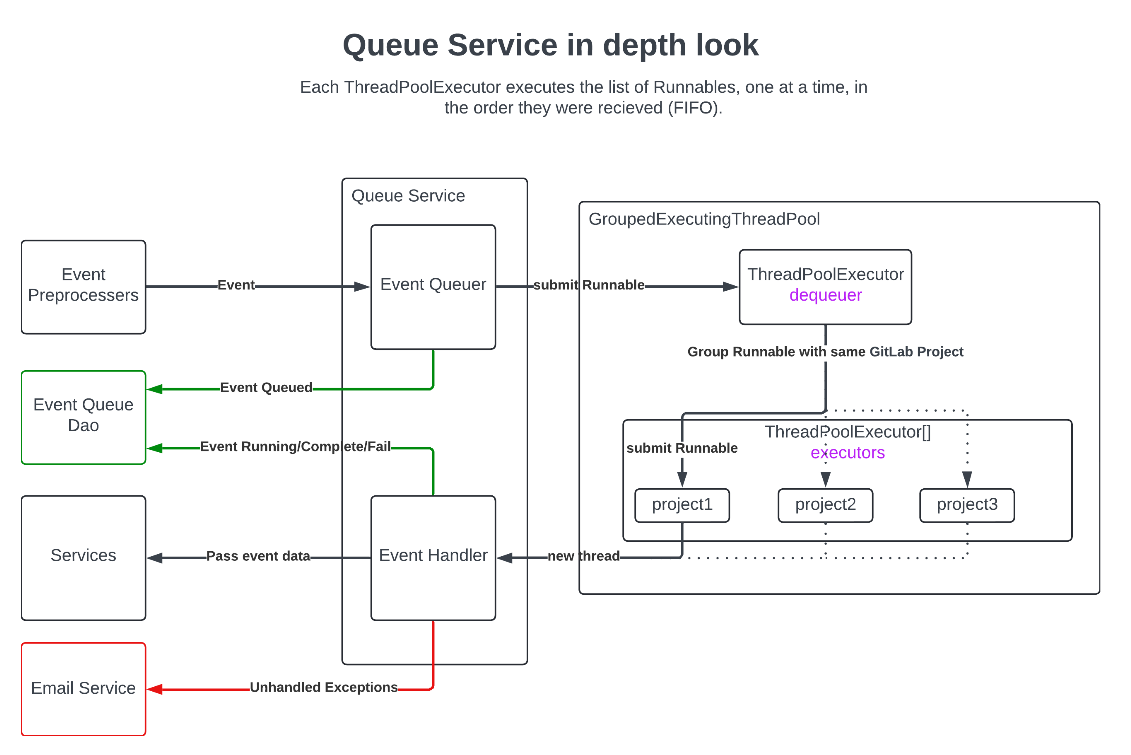 An in-depth diagram of Queue Service
An in-depth diagram of Queue Service
ArgoController
ArgoController receives events from Argo. When the source language files have completed translation and are ready in Argo, Argo will make a call to the GitLab Integration informing what has completed, which it receives via the ArgoController. From there, the GitLab Integration will grab the translated file, create a branch and MR if necessary, and the commit to that branch. Future developments could have Argo making various other calls, such as querying the if the Translation MR has been merged to display in Argo. Such possible future calls would be added to the ArgoController.
Event Queuing
The QueueServiceImpl implements a sophisticated event queuing system that handles concurrent processing while maintaining project-specific FIFO (First-In-First-Out) ordering. The system processes events after their initial pre-processing within HTTP requests, managing both database persistence and in-memory queuing.
Event Reception and Storage
When an event is received by the QueueService:
- The event data is stored into the database for logging and retry capabilities,
- An
EventRunnableobject is created, containing both the event data and its execution function, and the function will be executed on a new thread and use the provided event data, - The
EventRunnableis submitted to aGroupedExecutingThreadPool.
Queuing Implementation
The system uses a two-level threading approach:
- Primary ThreadPoolExecutors (
dequeuer): Receives all incomingEventRunnablesin their initialFIFOorder, - Secondary ThreadPoolExecutors (
executors): An array of executors where each entry is dedicated to processing events for a specific GitLab Project
Concurrent Processing Rules
- Events within the same Project must be processed synchronously in
FIFO(First-In-First-Out) order, - Different Projects can be processed concurrently, up to a maximum of 5 Projects at once,
- If an event is next in queue for a Project that cannot be processed (due to the 5-Project limit), it will block all subsequent events regardless of their Project,
- Events that arrived before the blocked event continue processing normally.
Event Status Tracking
The system maintains event status in the database with the following states:
- Queued: Initial state when event is received
- Running: Event is currently being processed
- Completed: Event has finished processing successfully
- Failed: Event processing encountered an error
Execution Process
- The event thread begins execution in the
QueueService#handleEventmethod - Based on the event type, it is dispatched to the appropriate service:
- GitLab service
- Argo service
Purpose and Benefits
- Synchronous Processing: Maintains FIFO order within Projects to prevent race conditions
- Concurrent Optimization: Allows parallel processing across different Projects for improved throughput
- Resource Management: Limits concurrent Project processing to prevent resource overuse and API rate limit issues
- Reliability: Database persistence enables event tracking and retry capabilities
- Scalability: ThreadPool architecture enables efficient thread management and execution
Merge Request closed
GitLabMergeRequestService#handleClosedEvent Anytime an MR is closed on the monitored projects, this event is called.
- Get Merge Request data from GitLab API
- Purpose: Not all needed data is provided in the Event. It will also get the latest data in case there were changes since the event was called.
- Get a list of files needing translation
- This depends on the translation MR and the contents of the changed files in the MR.
- Get the contents of those files
- Create the Argo Request for those files
- Add cards (see definition below) and allocate assets in the Request
- Purpose: Provide additional data like links, and organize the Schedule so it’s ready to launch, or can be auto launched.
- If any exception happens, delete the Argo Request so it’s not incomplete.
Quick notes:
What data is contained in an Argo Request?
You can see an example here. Requests contain data about GitLab, the TMS it’s connected to, and who worked on the Request such as comments and assignees. The following information from the GitLab integration is put into a Request:
- Project ID and Path,
- Merge Request ID and title and URLs,
- Components,
- File names and contents of files that will undergo translation.
What is a “card?"
In a Request, you can have fields with one single value. Such as “Project ID”. Cards are like a mini table rows that just hold data. Each card can have fields with single values, but multiple cards can be added to a Request. Their values are tabulated onto a table within the Request, where each row is a card, and each column is one field. We use Cards for the GitLab Integration to list all relevant URLs so it makes it easier for Request viewers to go from the Request screen to the MRs.
Argo Commit to GitLab
GitLabMergeRequestService#handleCommitToTranslationMREvent Whenever translation has completed on a target file, Argo attempts to commit the file back to GitLab. It will do this one file at a time.
- Get details from Argo about the Request and the Plan and its content,
- Get details from GitLab about the Project,
- Get the Translation YAML and decide where to place the target files based on this
- Will attempt to find the file path in the Argo Translation YAML (the configuration file that has the information on folder locations) for the source file, then remap to the target language.
- Commit the file and its contents to a Translation MR
- Update Argo that the step is completed
Deployment Phase(s)
The deployment for the Argo<->GitLab Integration will be handled in two phases.
Phase 1 - Spartan
The first phase will have the application deployed in Spartan’s environment to expedite the process of running and testing the application. It is only a temporary step until the application can ultimately be deployed to GitLab’s environment.
The application is built using GitLab’s CI/CD Pipeline. The artifact is then downloaded and deployed by the Spartan Software engineers.
The application is deployed in a Rocky Linux 8 OS running on AWS EC2. It’s runs on Java 17, with an Nginx proxy. It runs on the same instance as the Argo application. The nginx application is configured to allow only the endpoint for GitLab webhook events to access the application. All other endpoints can only be accessed within the box via localhost. The database is hosted in Amazon RDS, with the only allowed connections being that specific EC2 instance and engineers on the VPN. There is both a production version of this setup, and a test version of this setup. So there are two of each of the databases and EC2 instances, but prod and test cannot communicate with one another.
Phase 2 - GitLab
- Pipelines:
- When the GitLab environment is ready, it will work the same for building in the Pipelines from the same repository.
- However, pipelines would run to build the executable java(.jar) plus build the docker container image, that includes Java 17 and nginx to act as a proxy.
- Google Cloud:
- To configure the database part of the Argo-GitLab integration service, we can install and deploy the database services on Google Cloud Sandbox, and use Cloud SQL to connect from runway.
- More implementation details are documented here and here.
- Runway:
- It get’s deployed in Runway from the docker image following Runway onboarding (onboarding details are documented here and here).
- Runway service connects to the cloudSQL instance outside of the runway GCP projects using private IP + private service connect
Alternative Solutions
One quick solution is to build a linux server in to Google Cloud and install the java application and the rest of the database configuration on cloud. We can call this as Traditional VM based deployment whether it’s done on the cloud or somewhere inside GitLab:
- Quick initial setup using Google Cloud VM with Java application and database
- Minimal initial configuration required
- Lower initial development overhead
However, it has some serious limitations:
- Deployment challenges:
- Manual deployment process requiring executable JAR rebuilds
- Lack of zero-downtime deployment capabilities
- No automated rollback mechanisms
- Risk of configuration drift between environments
- Operational concerns:
- Pipeline interruption during deployments
- Potential data loss during Argo communications
- Limited scalability options
- Higher maintenance overhead
- Monitoring and recovery:
- Limited built-in monitoring capabilities
- Complex disaster recovery procedures
- No automatic failover options
eef3c341)
