Siphon
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| ongoing |
ahegyi
|
andrewn
abrandl
|
dennis
|
devops monitor | 2024-11-20 |
Summary
This document describes the architecture of the MVP version of Siphon, which delivers serialized CDC (change data capture) data from the PostgreSQL logical replication stream to a queueing system. From the queueing system, consumers can process the data and ingest it into other database systems (e.g. ClickHouse, Snowflake).
Project goals
- Replace existing data synchronization tooling by providing a standard way of getting data out of the PostgreSQL databases.
- Asynchronously streaming data change events from our PostgreSQL databases via pub-sub.
- Possibility of extracting data from existing tables in a consistent manner.
- Intended to be deployed through Kubernetes environment on GitLab.com, Dedicated and Self-Managed through the Cloud-Native GitLab Charts (and Omnibus).
- The tool is mostly transparent to application developers making changes to the Rails application.
- Zero or minimal impact on the availability of the PostgreSQL cluster.
- Must support Self-Managed Postgres version 14 and above clusters (with and without Patroni). Additionally it must support Cloud-Managed Postgres Clusters via Amazon RDS and Google CloudSQL, using only features and extensions available in these managed services.
Project non-goals
- The system will only support PostgreSQL replication. Other types of data changes such as Redis or Git changes will not go through the Siphon application. The queueing system for such changes might be the same.
- The system will not allow the application to emit custom events. All events will originate from the Siphon producer which are logical replication events or row data from the initial data snapshot process. The origin of the data will be always the PostgreSQL database.
Main components
The main components of Siphon are:
- Producer application (single-binary application):
- Manages a PostgreSQL publication.
- Reads data from the replication slot.
- Orchestrates an initial data snapshot from existing tables.
- Serializes and enqueues CDC events.
- Pluggable Queueing/PubSub system (TBD, we’re evaluating NATS)
- Durable data store.
- Provides at-least-once delivery guarantees. (to be verified if we require exactly-once delivery guarantees)
- Capable of storing/buffering large tables (2–3 terabytes).
- Pluggable configuration with the possibility of supporting different queueing systems.
- Consumer application (single-binary application):
- Connects to a target database system.
- Reads CDC events from the queue.
- Reformats the events and pushes the data to the target database system.
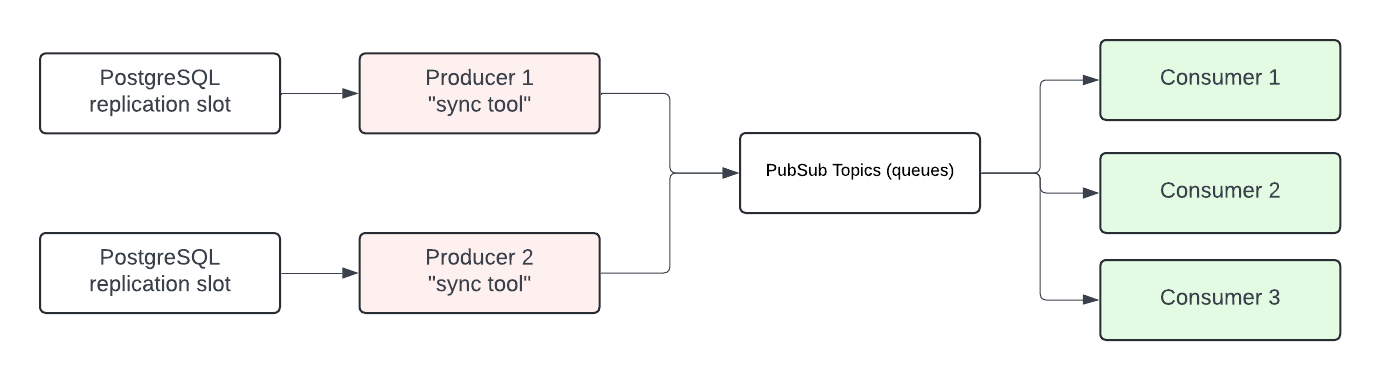
Motivation
The PostgreSQL database in gitlab-rails is not optimized for analytical workloads. Over the years, teams (Optimize, Analytics) have faced several challenges when architecting scalable analytical features. While these features work, they require substantial engineering investment (background aggregations, denormalization), significantly affecting team velocity and often leading to optimizations specifically catering for the OLTP database, rather than our ability to provide data analytics.
Additionally, running analytical workloads in our OLTP database has led to numerous production incidents over the years, and adds unnecessarily to production load.
By adopting the ClickHouse analytical database, we now have a scalable solution to support the existing analytical features within GitLab. The main challenge becomes data synchronization. Currently, we have at least 3 distinct methods to synchronize data from PostgreSQL to ClickHouse. These solutions are often tailored to specific problems, making generalization difficult (periodical workers to send data, consistency workers to ensure data consistency). Some of these synchronization strategies are implemented specifically for GitLab.com. Establishing a unified approach to transferring data from PostgreSQL to other database systems will greatly simplify and streamline our data synchronization processes, reducing fragmentation and enhancing overall efficiency.
With a tool like Siphon, we can efficiently make PostgreSQL database tables available in other database systems with minimal lag.
Other possible use cases for Siphon:
- Contributing towards to the data unification effort by consolidating all data synchronization implementations from the PostgreSQL database.
- Replicating the production database to Snowflake for the data team.
- Implementing advanced analytics capabilities for all GitLab features beyond Optimize and Platform Insights.
- Real-time threat and abuse detection by the Trust and Safety team with their Omamori project.
- Building GitLab features that can react asynchronously to database changes.
- Providing customers a way to stream data changes.
Alternative options
We have considered the following tools:
- PeerDB
- It was recently acquired by ClickHouse and they give less or no focus on other data warehouses.
- Debezium
- Debezium requires Kafka (this can be a problem for self-managed instances) and brings in a lot of new dependencies.
- Airbyte
- Significant limitations, including no support for schema changes.
We haven’t found a tool that supports gradual rollout by adding tables one at a time to a PostgreSQL publication with initial data snapshotting capabilities. During the PoC phase, we found a procedure that achieves this in an eventually consistent manner, assuming that we provide at-least-once delivery guarantees (allowing for duplicated events).
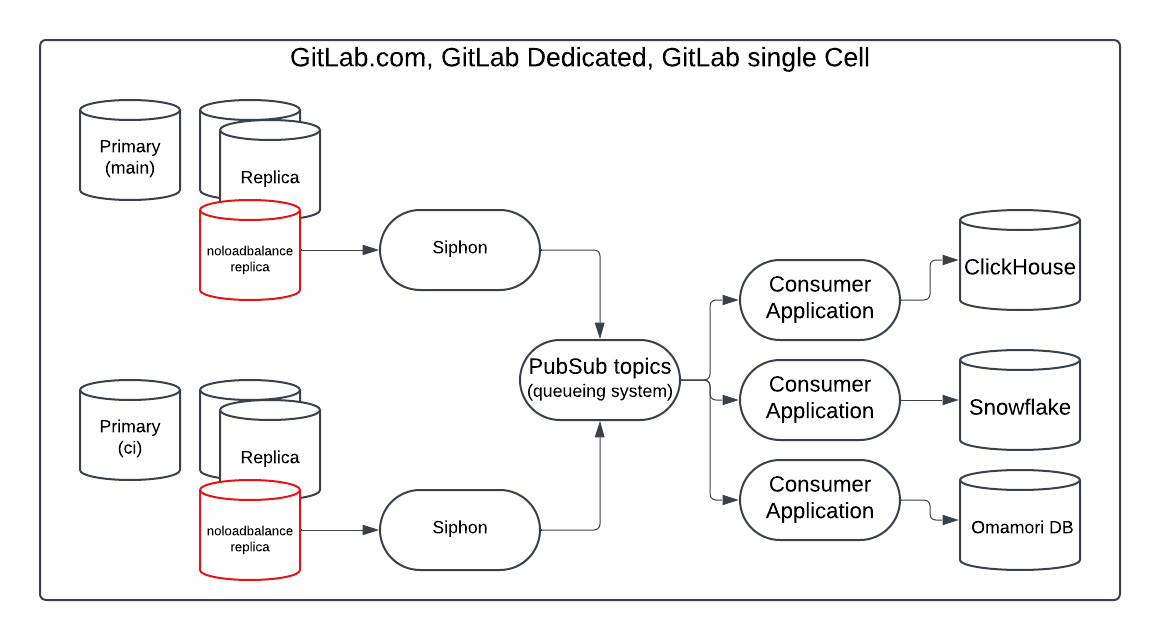
Infrastructure Diagram
This diagram shows a deployment for GitLab.com, where we have one consumer application ingesting data into ClickHouse. The MVP will also include another consumer application for ingesting data into Snowflake.
Future state: multiple cells
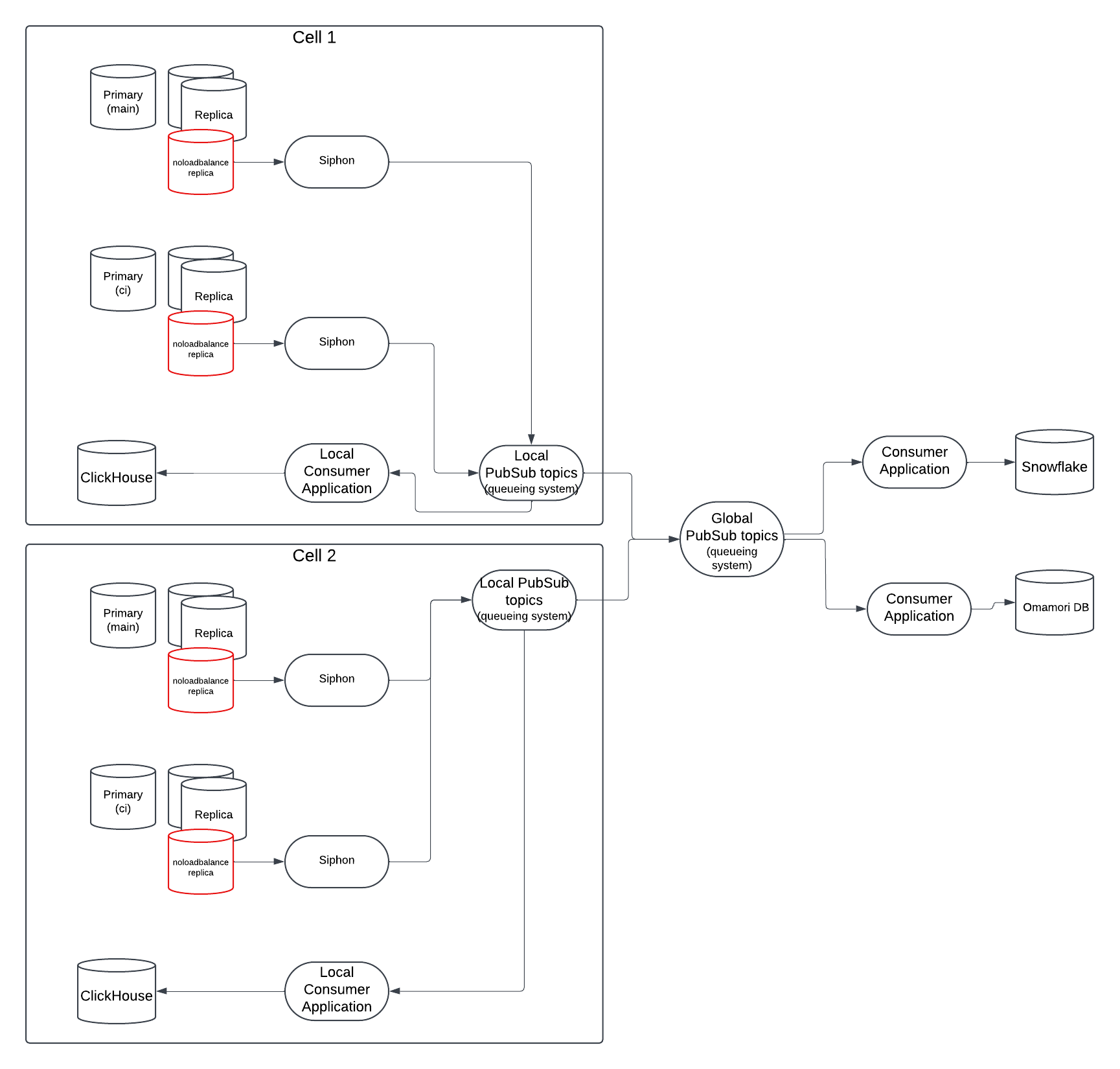
In a multi-cell environment we will have two kinds of consumers:
- Global consumers: can receive data from all cells.
- Local consumers: can only read queues from the cell where they are deployed.
Note: The setup might alos include cell-local queueing systems where a special consumer would push data from the cell-local queueing system to a global queueing system (GitLab.com only).
Producer Application Components
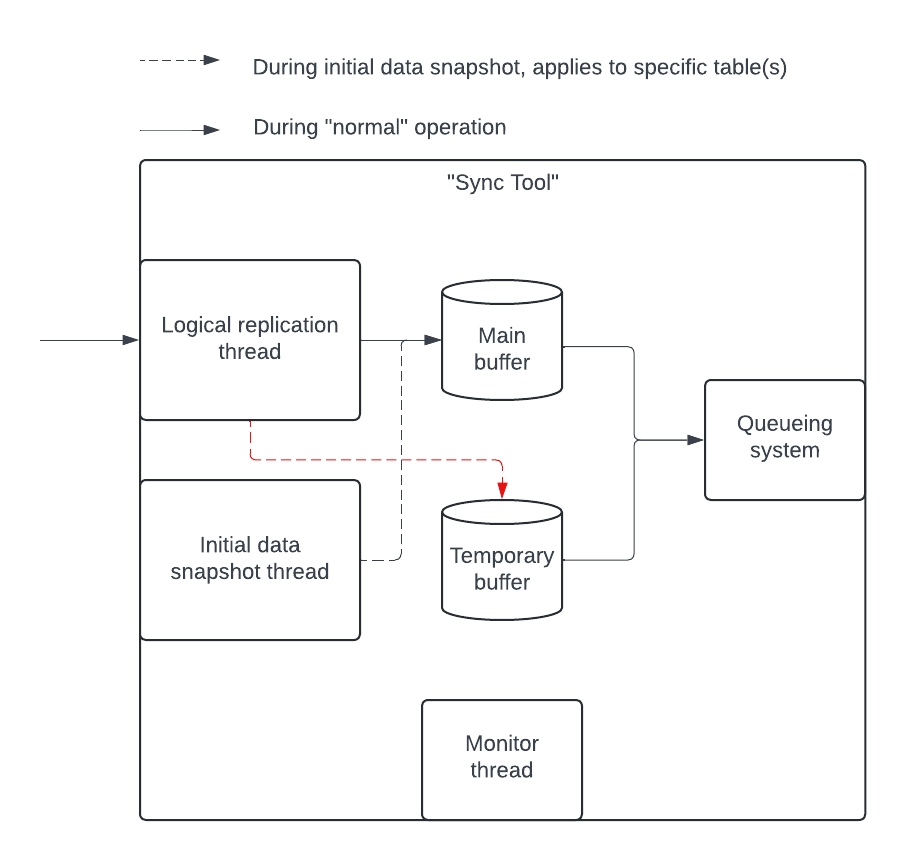
- Lock goroutine: Ensures that only one instance of the application is connected to the PostgreSQL DB with the given application id (configuration). It uses advisory locks (related issue).
- Logical replication goroutine: Reads the logical replication stream and pushes data to the main buffer.
- Initial data snapshot goroutine: Captures data from existing tables. This goroutine is mostly idle after initial data snapshot is done.
- Monitor goroutine: Periodically collects statistics.
Initial data snapshot procedure
When creating the publication for the first time, as the first step, the application will need to read the existing data from the database tables. This requires one or more extra connections to PostgreSQL. A high level process for the initial data snapshot (for one table) can be the following:
- Ensure that the configured PostgreSQL server for the initial data snapshot is caught up to the LSN that altered the
PUBLICATION(table added). - Inspect and determine the table size and the number of blocks it uses.
- Using the number of blocks, we can determine N ranges which can be processed by N threads (can be configured).
- Read the data in the batches, serialize and send the payload to the queueing system. Using efficient TID range scan.
The first step is important to ensure consistency in case we use a second physical standby server for the initial data snapshot.
During the initial data snapshot all records will be INSERT statements, the order in which we send the batches to the queueing system does not matter. While the initial data snapshot is taken, we must not enqueue any data from the logical replication stream for the given table.
To take a consistent snapshot from the PostgreSQL database we would need to export a snapshot and keep the connection that exported the snapshot open while the threads are exporting the data. For very large tables this process can take very long time (hours) which means that in case of an application error or closed connection we would need to restart the snapshot process. This is a critical process that might hold onto locks for longer than usual period of time (if it’s not invoked from a hot_standby_feedback=off replica). For this reason we should try to make making the data snapshotting process as fast as possible.
Exporting a snapshot:
BEGIN;
SELECT pg_export_snapshot(); -- '00000006-00053166-1'
-- keep the connection open
Do this for every connection that reads data from the table:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET TRANSACTION SNAPSHOT '00000006-00053166-1'; -- use the exported snapshot
SELECT ... -- query the table
Data serialization
We plan to use protobuf as our serialization format because of its low space usage and fast serialization performance. While we read from PostgreSQL’s default output plugin for logical decoding (pgoutput) for portability, Siphon will convert the received data into protobuf format.
The protobuf schema would express the column list as an array which would help handling database schema changes without rebuilding and redeploying the application. This means that some extra complexity of handling database column changes will need to be added to the consumer applications.
An example JSON representation of one “package” which might be pushed to the queueing system:
{
"table": "issues",
"schema": "public",
"application_identifier": "prd.cell1.main.1",
"events": [
{
"operation": "INSERT",
"timestamp": "2018-12-10T13:45:00.000Z",
"columns": [
{
"name": "id",
"int64_value": 12
},
{
"name": "title",
"string_value": "My issue"
}
],
},
{
"operation": "DELETE",
"timestamp": "2018-12-10T13:45:30.000Z",
"columns": [
{
"name": "id",
"int64_value": 15
}
]
}
]
}
The package above includes two events. To prevent overloading the queueing system, the application will buffer events until a certain limit (size and time limit) and serialize the events into one package per table. For example if during a 3 second window (configurable) we receive 30 events for issues and 15 events for projects, then the application would push 2 packages to the queueing system.
Scaling
Potential bottlenecks:
- PostgreSQL logical replication slot cannot decode WAL data fast enough.
- Siphon cannot read the logical replication stream and serialize the data fast enough.
Both of these could be addressed by scaling horizontally, running multiple Siphon producer applications with different table configurations. A Siphon instance could be connected to a different PostgreSQL replica. For example:
- Application 1 replicates the main DB:
issues,users,merge_requeststables. - Application 2 replicates the main DB:
events,audit_eventstables. - Application 3 replicates the CI DB:
ci_buildstable.
Note: One deployed Siphon application should be performant enough to process our busiest table (or table partition). In the “worst-case” scenario, a dedicated application may be required for one table (unlikely).
Note: One PostgreSQL database can support multiple Siphon applications using different logical replication slots (default is 10 slots, changing this setting requires restart).
Data volume
Some initial logical replication event volume calculations were done during the PoC phase.
Currently we see 15k-25k logical replication events (INSERT, UPDATE, DELETE) per second per database (main, ci). Assuming that Siphon will not read logical replication events from all tables we would expect a single Siphon application to be able to handle 10k-15k logical replication events (read, parse, serialize, push to queue).
We can approximate the data volume if we pick a few tables and sample the row sizes, example:
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from issues t where id in (select id from issues TABLESAMPLE SYSTEM (0.001));
avg_row_size
-----------------------
1609.6599190283400810
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from projects t where id in (select id from projects TABLESAMPLE SYSTEM (0.001));
avg_row_size
-----------------------
376.8530259365994236
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from users t where id in (select id from users TABLESAMPLE SYSTEM (0.001));
avg_row_size
----------------------
458.2028985507246377
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from todos t where id in (select id from todos TABLESAMPLE SYSTEM (0.001));
avg_row_size
---------------------
97.5580929487179487
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from notes t where id in (select id from notes TABLESAMPLE SYSTEM (0.001));
avg_row_size
----------------------
895.0119381293470362
Assuming a pessimistic case where the average event size is 1 kilobyte, Siphon would handle approximately 10-15 megabytes per second of incoming network traffic from PostgreSQL. By serializing and compressing the data, the payload size could be reduced by 20% to 40%. As a result, the queuing system would process a few (packaged) events per second (assuming events are sent every 3 seconds for the configured tables) with a total payload size of a few megabytes.
Database Schema Changes
In the MVP version of the tool, introducing database schema changes may require coordination with the teams responsible for managing the ClickHouse and Snowflake databases. To mitigate the risk of accidental schema divergence between PostgreSQL and downstream database systems, we will implement tooling to ensure consistency. Additionally, we plan to add CI tests into the GitLab application repository to provide notifications when such events occur.
For the MVP, we have identified the following database tables (main database only):
namespacesprojectseventsissuesmerge_requestsnamespace_detailsbulk_import_entitiesmilestonesnotes
It will eventually be possible to automatically handle database schema changes. Some ideas are described in this issue.
For now, this is how we will keep the database table schemas in sync:
- Add/Remove columns: CI test will notify us about the change.
- ClickHouse: We add an extra a migration to update the ClickHouse table schema (this can be automated).
- Snowflake: TBD
- Alter columns (rename, precision change, etc.):
- ClickHouse: Depending on the complexity, custom migration is needed.
- Snowflake: TBD
- Truncate table: not supported
- ClickHouse: Likely do a manual truncation or add an extra migration.
- Snowflake: TBD
ClickHouse DB will be generally easier to maintain since we have similar migration tooling like we have for PostgreSQL. The migration tool is already part of the deployment process.
Consumer applications
We plan to implement a detection and retry mechanism into these applications to ensure that the database schema is not outdated.
- When the application starts, request all database table schemas.
- When an event package is received from the pub-sub system for a specific table, compare the received column list.
- When the column list differs, request the table schema again (retry with backoff)
- When the column list matches, continue.
- Build an
INSERT INTOstatement with the column values. - Invoke the
INSERT INTOstatement. - Mark the event/item as processed for the pub-sub system.
When the column list differs and a timeout is reached, stop trying processing events data. Alerting and manual intervention will be needed.
Custom consumer application development
During the MVP phase, we don’t intend to support consumer application development. We plan to have two applications developed for ClickHouse and Snowflake databases.
Authorization and data access
Access control to specific queues will be handled by the queueing system (for example NATS has advanced authorization configuration options).
Data filtering
Sensitive data such as hashes and keys must be filtered out on the producer level. Siphon’s configuration should allow us to specify which columns should be skipped from the logical replication stream.
The list of database columns will come from a well-known, audited system, for example from a data catalog.
Handling red data
Handling red data and filtering out specific columns before inserting into the target database systems will be the responsibility of the consumers. The consumers might request metadata from an external source (for example the data catalog) about the data classification of specific database columns.
Project Management
The work is tracked in the Siphon project. There is an epic for the MVP.
Language: Golang
We plan to use Golang with the following libraries:
- Reading logical replication stream:
pglogrepl - Connecting to the PostgreSQL database:
pgx - Connecting to the queueing system:
nats.go(NATS is still under evaluation) - Data serialization library:
protobuf - Compression library: TBD (we plan to use
zstd)
Monitoring
The application will expose a HTTP endpoint that provides metrics data for consumption by Prometheus (setup issue, adding more metrics issue):
- Stats about the processed data (number of
INSERT,DELETE,UPDATEevents per table). - Timings for each processing step (parsing, serializing).
- Buffer sizes.
- Memory usage.
- Info about the replication lag (PostgreSQL side). Keep track of the not consumed data volume from the replication slot.
Some of this data should also be logged to integrate the application with our logging system (Kibana).
Encryption
Connections to the database and the pub-sub (queueing) system will utilize secure TLS connections to ensure data security during transmission.
Encrypting and decrypting messages within the Siphon application will not be necessary if the compute nodes running the pub-sub system have full-disk encryption enabled.
Requirements:
- TLS/SSL connectivity to:
- PostgreSQL
- ClickHouse
- Snowflake
- The pub-sub system
- Full-disk encryption for the pub-sub system’s storage.
NOTE: For more context, see the discussion issue.
Failure scenarios
PostgreSQL connection is closed
The application will retry a few times and then exits.
In case the initial data snapshot connection is closed, the whole snapshot process needs to be cleaned up. This error would not be recoverable and the snapshot process would need to be started again from the beginning (drop all exported data).
Queueing system is not available
The application will retry a few times and then exits.
Payload rejected by the queueing system because the topic/queue is not available
Use a retry mechanism.
The application crashes
The environment should ensure that the application is restarted.
The Siphon pod is terminated
The environment should detect this and start a new instance. The producer application does not persist data on the local disk.
Runtime risks
Logical replication on the PostgreSQL database server can consume a significant amount of resources. To minimize the impact on the primary database, we plan to use replicas for reading the logical replication stream and taking the initial data snapshot.
Issues and mitigations
Siphon is down or not consuming WAL data
- Problem: Accumulation of WAL files on the replica, leading to high disk usage.
- Mitigation:
- Monitor replication lag and the number of WAL files.
- Define a threshold (“point of no return”) to drop the replication slot if necessary.
Database replica is gone or replication slot is dropped
- Problem: Replication cannot be resumed in a consistent manner.
- Mitigation:
- Perform a full re-sync (initial data snapshot) of the data.
- Ensure consumers and downstream systems can rebuild/restart the sync process from scratch, including necessary cleanup steps.
Performance issues on PostgreSQL
- Problem: Logical decoding lag growing – unable to keep up with rates of writes.
- Mitigation:
- Scale horizontally, use multiple Siphon applications with different replica servers.
Consistency
- Problem: Missing WAL record(s) due to a bug or switchover/failover.
- Mitigation:
- Assess the impact on the target database system and decide whether we need to resync the databases.
Future considerations
PostgreSQL 17 is expected to introduce a feature to synchronize logical replication slots. This feature could prevent failures that require a full data resync, making logical replication more robust.
Deployment
External dependencies
Producer application:
- Connection to a PostgreSQL server configured for logical replication (PostgreSQL v14+).
- Connection to a queueing system.
Consumer application:
- Connection to a queueing system (e.g., NATS).
- Connection to the target system (e.g., ClickHouse, Snowflake).
PostgreSQL Server(s)
With PostgreSQL 16, it’s possible to set up logical replication on database replicas. This allows Siphon to extract data with low latency from PostgreSQL without affecting the primary database or other read-only replicas used by the main GitLab application.
Optionally, the snapshotting process may use different PostgreSQL server. This is especially important for larger GitLab instances (GitLab.com). For GitLab.com we plan to use a physical standby working on streaming replication where we disable the hot_standby_feedback setting.
This allows us to take initial data snapshot without affecting the cluster (long transaction, blocking vacuum).
Infrastructure needs:
- One node for running the producer application (after the MVP we will run multiple applications).
- One or more nodes for running the consumer applications (1 application per target database).
- A cluster for running the queueing system (TBD).
Rollout
The tool will be built to allow gradual addition of tables via a configuration file. When a new table is added, the system will take an initial data snapshot as the first step and then it continues with the changes captured via the logical replication stream.
After MVP Steps
- Automated schema detection from the GitLab application.
- Multiple instances of the application running (CI, Main, Sec databases).
- A coordinator application to dynamically alter producer configurations.
- Dedicated, self-managed support.
eef3c341)
