Cells: 1.0
NOTE: The phase names Cells 1.0, 1.5, and 2.0 are replaced by Protocells.** A lot of work done in Cells 1.0 carries over to Protocells as is.
This document describes a technical proposal for a Cells 1.0.
Cells 1.0 is a first iteration of the cellular architecture. The Cells 1.0 target is to deliver a solution for internal customers only, and be a foundational step for next iterations, to be able to deliver something with a smaller scope.
Cells 1.0 is a complete working feature that is meant to be deployed to GitLab.com SaaS.
Read more about Cells 1.5, which is meant to provide a mechanism to migrate existing customers and is built on top of the Cells 1.0 architecture.
Read more about Cells 2.0, which is meant to support the public and open source contribution model in a cellular architecture.
Preamble
A Cells 1.0 is meant to target internal customers that have the following expectations:
- They want to use our multi-tenant SaaS solution (GitLab.com) to serve their Organization.
- They accept that they may receive updates later than the rest of GitLab.com. Note that when GitLab does a patch release, the Delivery team makes sure that production (every cell) runs the patch release version before making the release public. This does not mean that outside of a patch release, all the cells run the same version of GitLab. See this private discussion for more information.
- They want to use an environment with higher degree of isolation to rest of the system.
- They want to control all users that contribute to their Organization.
- Their groups and projects are meant to be private.
- Their users don’t need to interact with other Organizations, or contribute to public projects with their account.
- Are OK with being unable to switch Organizations with their account.
From a development and infrastructure perspective we want to achieve the following goals:
- All Cells are accessible under a single domain.
- Cells are mostly independent with minimal data sharing. All stateful data is segregated, and minimal data sharing is needed initially. This includes any database and cloud storage buckets.
- Cells need to be able to run independently with different versions.
- A cluster-wide service is provided to synchronize state between all Cells.
- A routing solution that is robust, but simple.
- All identifiers (primary keys, user names, group, and project paths) are unique across the cluster, so that we can perform logical re-balancing at a later time. This includes all database tables, except ones using schemas
gitlab_internal, orgitlab_shared. - Because all users and groups are unique across the cluster, the same user can access other Organizations and groups at GitLab.com in Cells 2.0.
- The overhead of managing and upgrading Cells is minimal and similar to managing a GitLab Dedicated instance. Cells should not be a linear increase in operational burden.
- The Cell should be deployed using the same tooling as GitLab Dedicated.
This proposal is designed to cut as much scope as possible but it must not make it impossible to meet the following long-term goals:
- Users can interact with many Organizations.
- Cells can be re-balanced by moving Organizations between Cells.
- The routing solution can dynamically route requests.
Proposal
The following statements describe a high-level proposal to achieve a Cells 1.0:
-
Terms used:
- Cell: A single isolated deployment of GitLab that connects to the Topology Service.
- Topology Service: The central service that is the authoritative entity in a cluster. Provides uniqueness and routing information.
-
Organization properties:
- We allow users to create a new Organization on a Cell. The chosen Cell would be controlled by GitLab Administrators.
- The Organization is private, and cannot be made public.
- Groups and projects can be made private, but not public.
-
User properties:
- Users are created on the Cell that contains the Organization.
- Users are presented with the Organization navigation, but can only be part of a single Organization.
- Users cannot join or interact with other Organizations.
- User accounts cannot be migrated between Cells.
- A user’s personal namespace is created in that Organization.
The following statements describe a low-level development proposal to achieve the above goals:
-
Application properties:
- Each secret token (personal access token, build token, runner token, etc.) generated by the application includes a unique identifier indicating the Cell, for example
us0. The identifier should try to obfuscate information about the Cell. - The session cookie sent to the client is prefixed with a unique identifier indicating the Cell, for example
us0. - The application configuration includes a Cell secret prefix, and the location of the Topology Service.
- User always logs into the Cell on which the user was created.
- Each secret token (personal access token, build token, runner token, etc.) generated by the application includes a unique identifier indicating the Cell, for example
-
Database properties:
- Each primary key in the database is unique across the cluster. We use database sequences that are allocated by the Topology Service.
- We require each table to be classified: to be Organization, or Cell-local.
- We follow a model of eventual consistency:
- All tables are stored in a Cell-local database.
- All cluster-wide attributes retain unique constraints across the whole cluster.
- The cluster-wide attribute are restricted to be modified by the Cell that is authoritative over the particular record:
- The user record can be modified by the given Cell only if that Cell is the authoritative source of this record.
- In Cells 1.0 we are likely to not be replicating data across cluster, so the authoritative source is the Cell that contains the record.
- All tables are stored in a Cell-local database.
- The Topology Service serves as a single source of truth for the uniqueness constraint (be it ID or user, group, project uniqueness).
- All Cells use gRPC to claim usernames, groups or projects.
- The Topology Service holds metadata information that allows to know on which Cell the username, group or project is.
- The Topology Service does not hold source information (actual user or project records), only references that are indicative of the Cell where that information is stored.
-
Routing properties:
- We implement a routing service that performs secret-based routing based on the prefix.
- The routing service is implemented as a Cloudflare Worker and is run on edge. The routing service defines a set of rules, and uses Topology Service to classify how to route data.
- Cells are exposed over the public internet, but might be guarded with Zero Trust.
Problems
The following technical problems have to be addressed:
- All secrets are prefixed as this is required by a simple routing layer to perform secret-based routing.
- All usernames, Organizations, top-level groups (and as result groups and projects) are unique across the cluster.
- All primary key identifiers are unique across the cluster.
GitLab Configuration
The GitLab configuration in gitlab.yml is extended with the following parameters to:
production:
gitlab:
topology_service:
address: https://cell1.gitlab.com
certificate: ...
secrets_prefix: kPptz
Topology Service
All services supported are described in dedicated documented about Topology Service.
Pros
- The proposal is lean:
- Each Cell holds only a fraction of the data that is required for the cluster to operate.
- The Topology Service is a single point of failure:
- Reduced set of features allows to make it highly-available service.
- Use highly-available database solution (Cloud Spanner).
- The routing layer makes this service very simple, because it is secret-based and uses prefix.
- Reliability of the service is not dependent on Cell availability. It depends on availability of Topology Service to perform classification.
- Mixed-deployment compatible by design.
- We do not share database connections. We expose APIs to interact with cluster-wide data.
- The application is responsible to support API compatibility across versions, allowing us to easily support many versions of the application running from day zero.
- Database migrations.
- Work out of the box, and are isolated to the Cell.
Cons
- We intentionally split cluster-wide data across all cluster cells.
- We effectively reinvent database replication to some extent.
- We are severely limited by how many attributes can be made cluster-wide. Exposing lots of data is a significant amount of additional code to allow cross-Cell interaction.
- We require all tables to be classified. We want to ensure data consistency across the cluster if records are replicated.
Features on GitLab.com that are not supported on Cells
For the initial deployment of Cells 1.0, we are cutting scope on some features to get something deployed. This doesn’t mean that Cells 1.0 is not going to support these in the future, but our application/infrastructure doesn’t support them yet.
The table below is a comparison between the existing GitLab.com features, and not self-managed/Dedicated.
| No Initial Support | Reasoning |
|---|---|
| GitLab Pages | Complexity. |
| CI Catalog | CI Catalog depends on public projects, organizations in Cells 1.0 can’t see public projects. |
| Organization Switching | A user belongs to a single organization. |
| Shared user accounts across Cells | Users will need to have new user accounts on each Cell for now |
| GitLab Duo Pro license works across all projects on instance | GitLab Duo Pro licenses, once granted, should allow users to use GitLab Duo Pro on all projects on the instance. With Cells 1.0, this will only work within their own cell. |
| User removal | Users can only be part of one Organization. A removal would equal a deletion in this case, so only user deletions will be offered in Organizations on Cells 1.0. Upon removal, there would be no way for a User to discover another Organization to join, as they are private for Cells 1.0. |
| Hosted runners on Windows and macOS | Hosted runners on Windows and macOS runners are still in beta and there are some more complex technical considerations related to cost. See the discussion: #434982 (comment 1789275416) on sharing resources. Self-managed runners are supported. |
| Multiple Sizes for Linux Runners | We will only support small linux runners on Cells 1.0. |
| GitLab for Jira Cloud app and GitLab for Slack app integrations | Jira and Slack apps can only be configured to post to single endpoints, so there is nothing in the configured endpoints’ routes that would allow the Cells router to know which cell to route to. We may need to support at the organization level. See #467791 and #467809 for more details. |
| Cross-organization downstream pipelines | Private organizations are in Cells 1.0 only and downstream pipelines would be unable to see public organizations. |
| Any feature dependent on Clickhouse | Clickhouse is not supported on Dedicated, which is the underlying provisioning tool for Cells. Clickhouse is also not supported in any of our other tooling such as Geo, Org Mover, Backup/Restore, etc. |
Any feature dependent on incoming email (mail_room) |
Cut scope. While we have a proposal to have ingest email per cell, we are yet to figure out how to have stable email addresses that can be used even when an organizations moves to a different cell. |
| Global search | Each cell will have an isolated search cluster. With Cells 1.0, global search will only work within the cell. See the Cells: Global Search design document for more details. |
| Paid subscription flows | CustomersDot relies on path based and OAuth token routing for Single Sign-On and fetching/updating data on GitLab. Without these, all requests from CustomersDot will go to the legacy Cell. |
| Legacy CI_JOB_TOKEN | The legacy CI_JOB_TOKEN cannot be routed because it does not contain routing information, and can be passed in the request body. Customers will need use the JWT format in order to be able to utilise CI_JOB_TOKEN outside of the legacy cell. |
| OAuth Provider OIDC Provider | OAuth/OIDC application provide a mechanism for third party and first party services to integrate to GitLab. Since cross cell communication is limited in cells 1.0, we can not reliably implement Oauth applications |
| Group SAML | Group SAML will not be available outside legacy cell open issue for cell 1.5 |
Phases
All Cells 1.0 work is tracked under the Cells 1.0 Epic. The Epic is split into multiple phases where each one represents a iteration to achieve Cells 1.0. Some of these phases have dependencies over one another, and some can be run in parallel.
Phase 1: PreQA Cell
Exit Criteria:
- New GCP organizations created.
- Break glass procedure.
- Ring definition exists.
- Cell provisioned using dedicated stack.
- Able to do configuration changes to Cell.
- Cell available at
xxx.cells.gitlab.com. - Cell doesn’t handle data uniqueness.
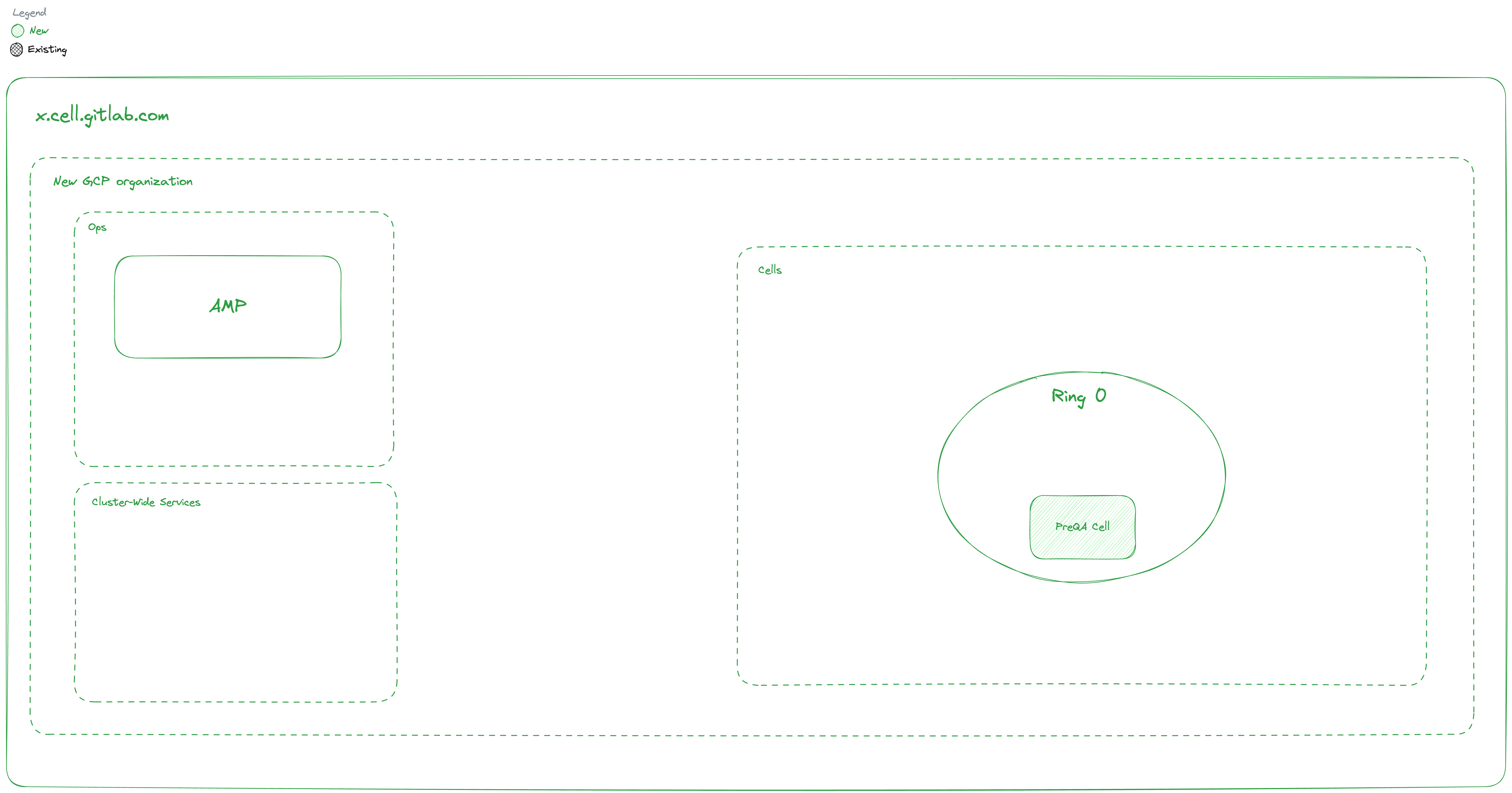
Unblocks:
- Phase 3: To provision runway deployment for Topology Service
- Delivery team: Start testing deploys on rings
Dependencies:
- None
Details:
Phase 2: GitLab.com HTTPS Passthrough Proxy
Exit Criteria:
- 100% of API traffic goes through router using passthrough proxy rule.
- 100% of Web traffic goes through router using passthrough proxy rule.
- 100% of Git HTTPS traffic goes through router using passthrough proxy rule.
- Requests meet latency target
- registry.gitlab.com not proxied.
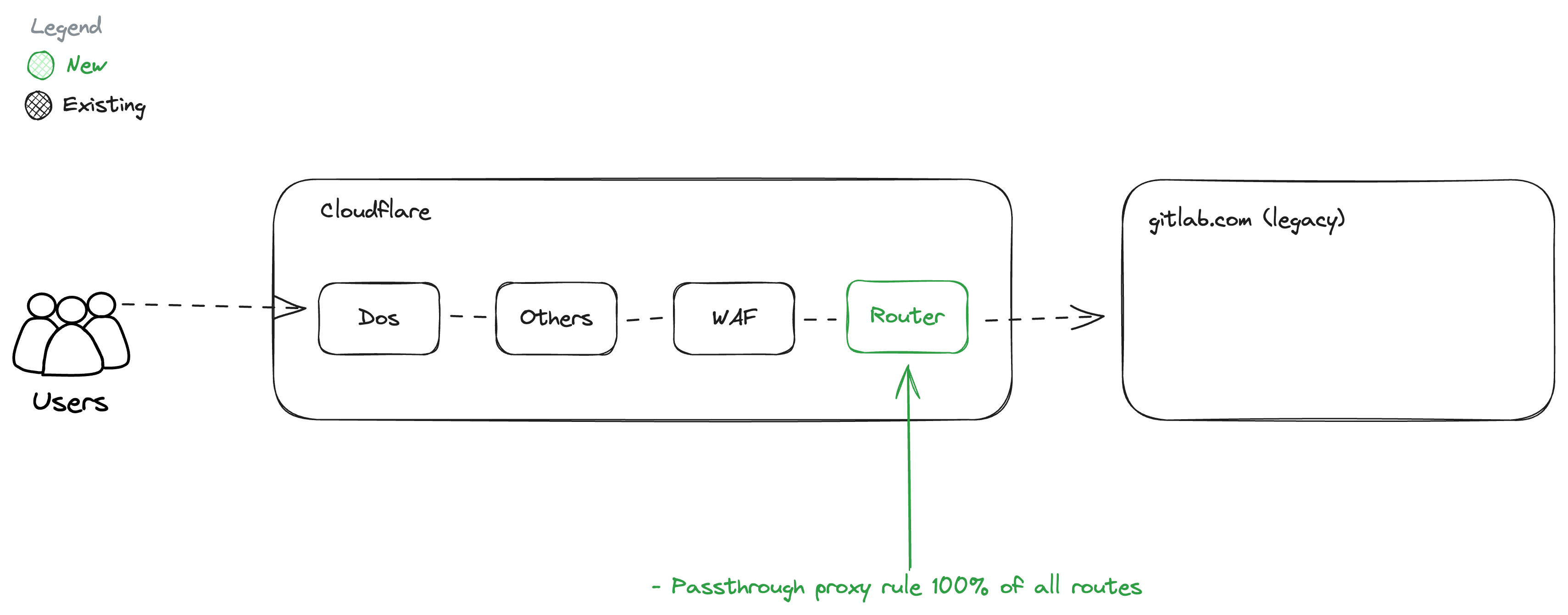
Unblocks:
- Phase 3: Router to be configured with additional rules in phase 3.
Dependencies:
- None
Details:
Phase 3: GitLab.com HTTPS Session Routing
Exit Criteria:
- PreQA Cell configured to generate
_gitlab_sessionwith prefix using rails config. - Route
_gitlab_sessionwith matching prefix to PreQA Cell using TopologyService::Classify (REST only) with static config file. - Continuous Delivery on Ring 0 with no rollback capabilities and doesn’t block production deployments.
- Topology Service Readiness Review for Experiment
- Topology Service gRPC endpoint not implemented.
Unblocks:
Before/After:
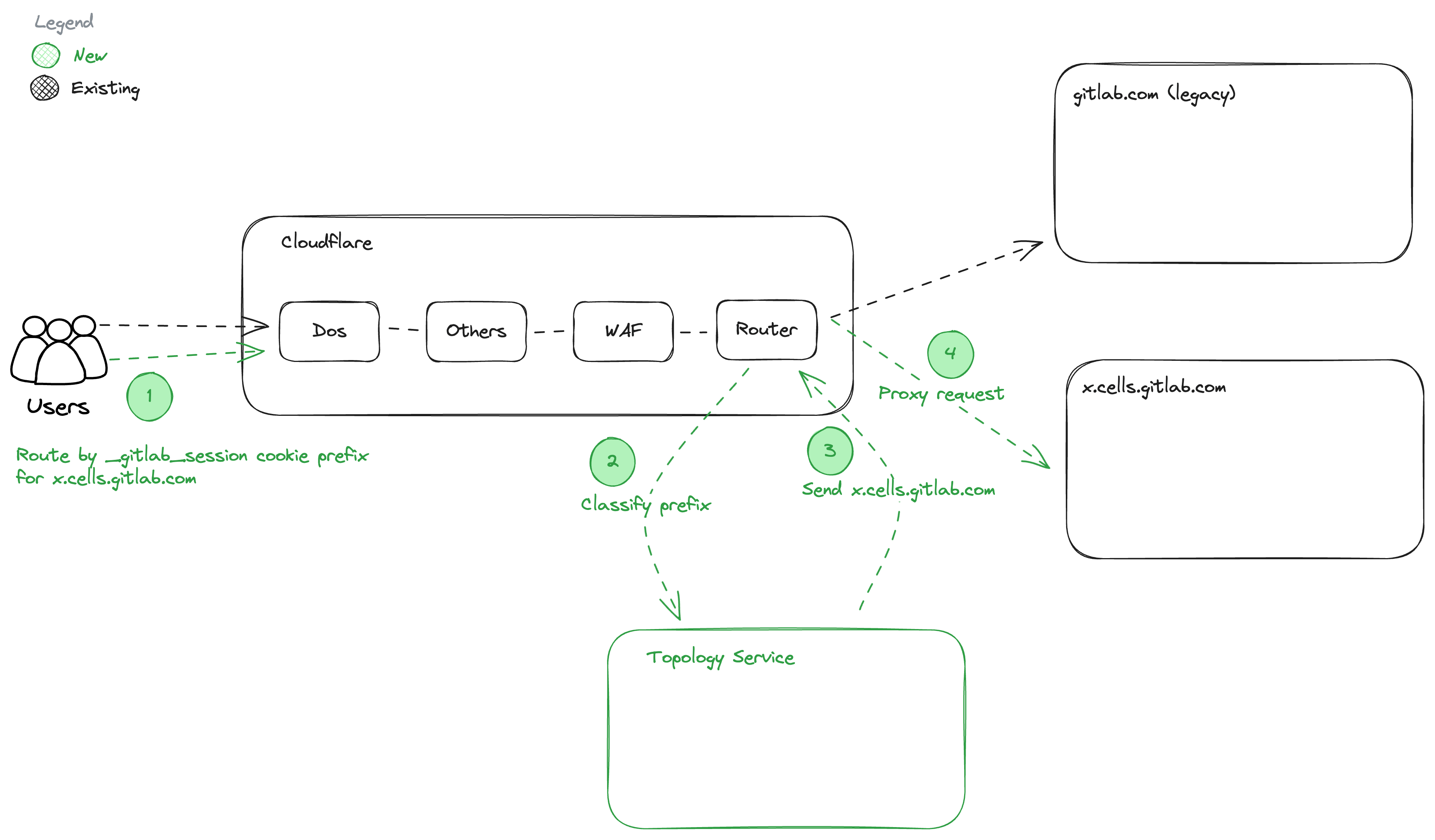
Dependencies:
- Phase 2: Passthrough proxy needs to be deployed.
- Phase 1: GCP organizations, Ring definition exists.
Details:
Phase 4: GitLab.com HTTPS Token Routing
Exit Criteria:
- Framework to generate routable tokens in Rails.
- Framework to classify routable tokens in HTTP Router.
- Topology Service being able to classify based on more criteria.
- Route Personal Access Tokens to different Cells using TopologyService::Classify.
- Support
PRIVATE-TOKEN:andAuthorization:HTTP headers for Personal Access Tokens, create issues for other to be solved in following phases. - Each routing rule added should be covered with relevant e2e tests.
- Route Job Tokens and Runner Registration to different Cells using TopologyService::Classify.
Dependencies:
- Phase 3: Topology Service and Router need to running in production.
Before/After:
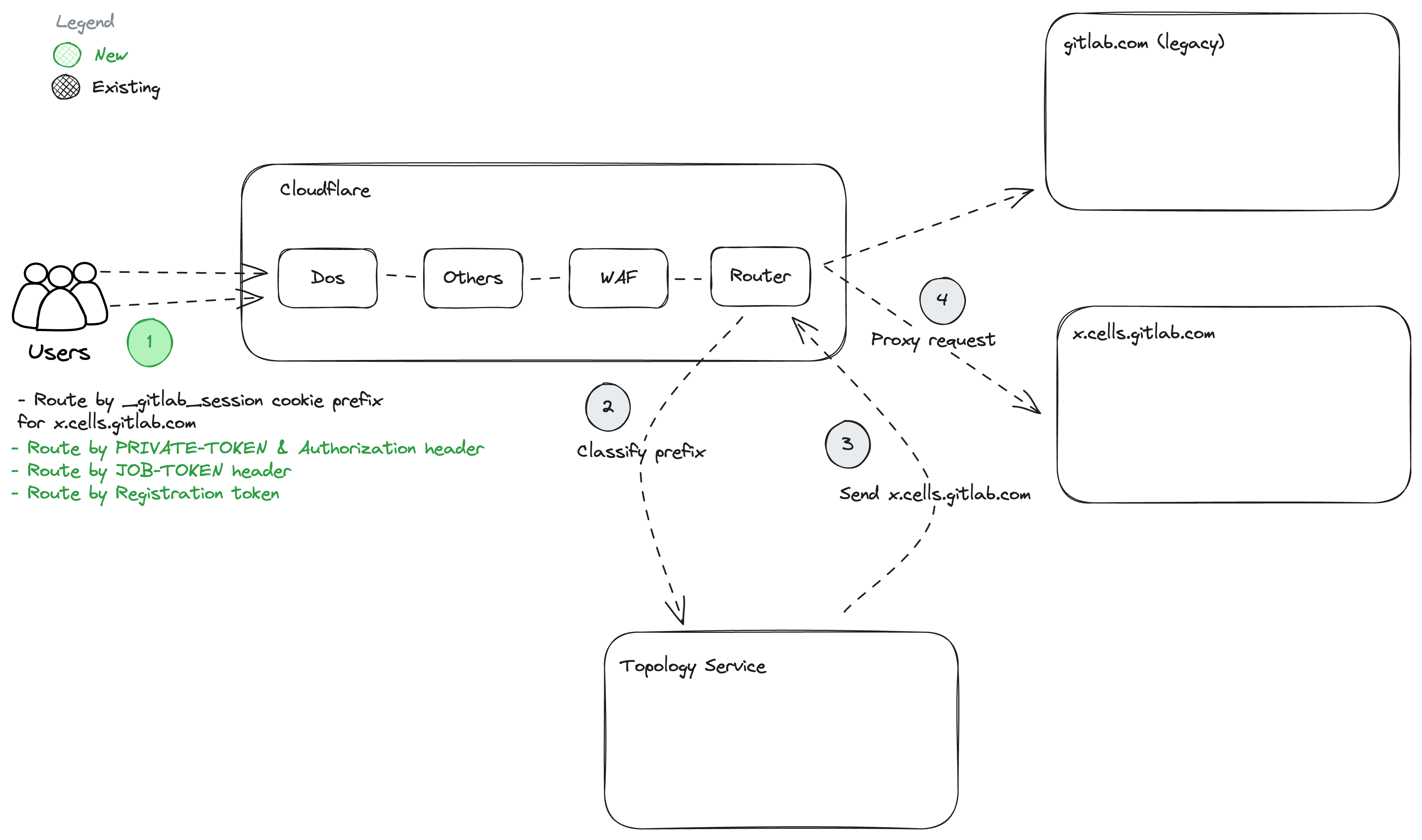
Details:
Phase 5: Cluster Awareness
Exit Criteria:
- Topology Service Production Readiness Review for Beta.
- Framework to claim resources globally using TopologySerivce::Claims storing them in Google Spanner.
- Following resources are claimable; Username, E-Mail, Top level Group Name, Routes
- All resources that need to be claimed identified.
- Unique indexes are audited, to not break any uniqueness required by application, and allows data migration.
- Lease a sequence to a Cell using ToplogyService::Sequence.
- Rails application able to send requests to TopologyService using internal network.
- mTLS communication between TopologyService and HTTP Router.
- mTLS communication between TopologyService and Rails.
- mTLS communication between HTTP Router and Cell.
- PreQA Cell can start claiming resources, still detached from Legacy Cell.
- Claims done by PreQA Cell will be deleted.
Dependencies:
- Phase 3: Topology Service Deployed.
Before/After:
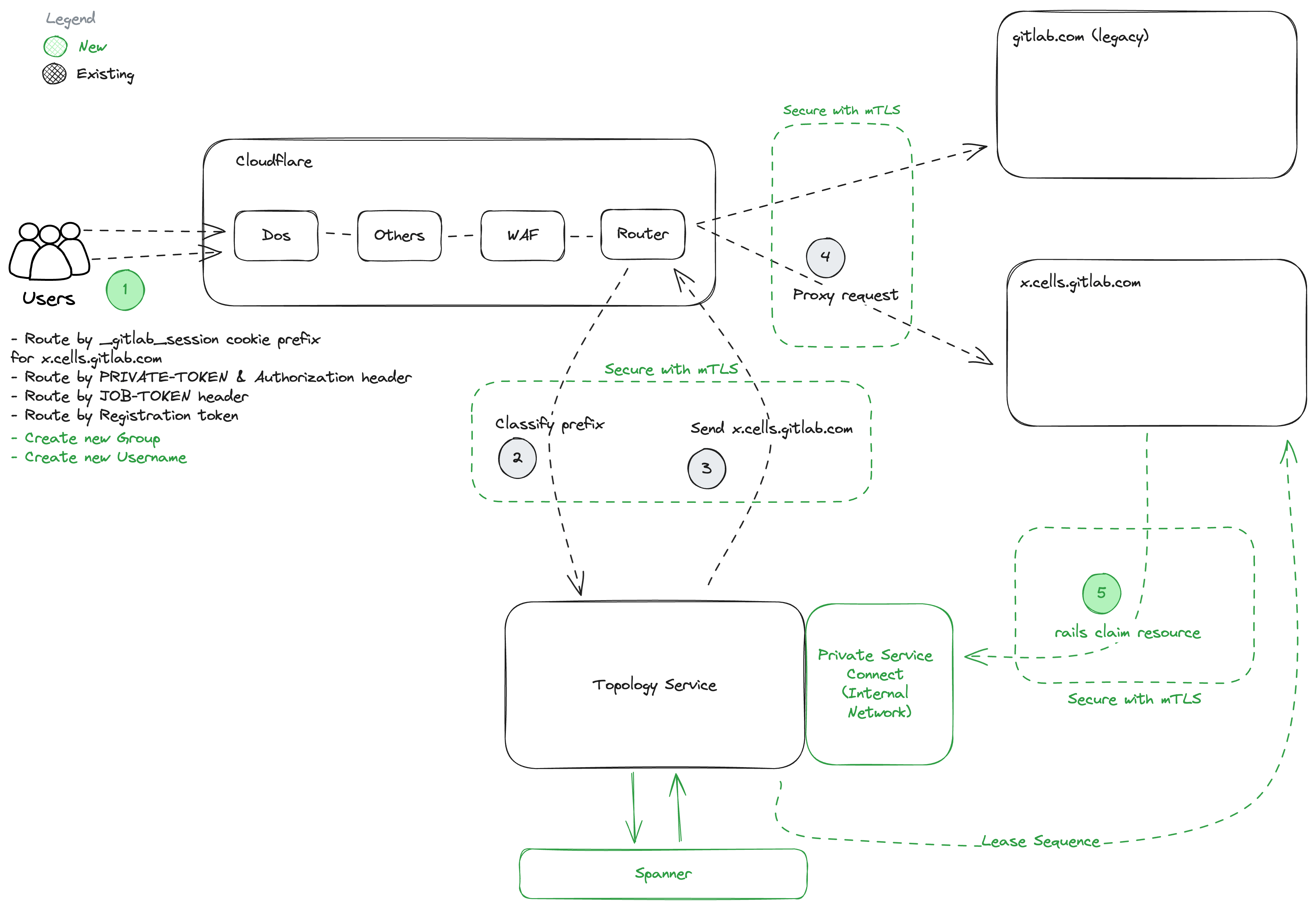
Details:
Phase 6: Monolith Cell
Exit Criteria:
- Topology Service Production Readiness GA.
- Legacy Cell configured as a Cell in TopologyService.
- All new resources in Legacy Cell are claimed using TopologyService::Claims.
- Legacy Cell claimed all existing resources.
- Sequence leased to Legacy Cell.
- Capacity Planning for sequences leased.
- Latency increase for creating globally unique resources up to 20ms.
Dependencies:
- Phase 5: Cluster Awareness
Before/After:
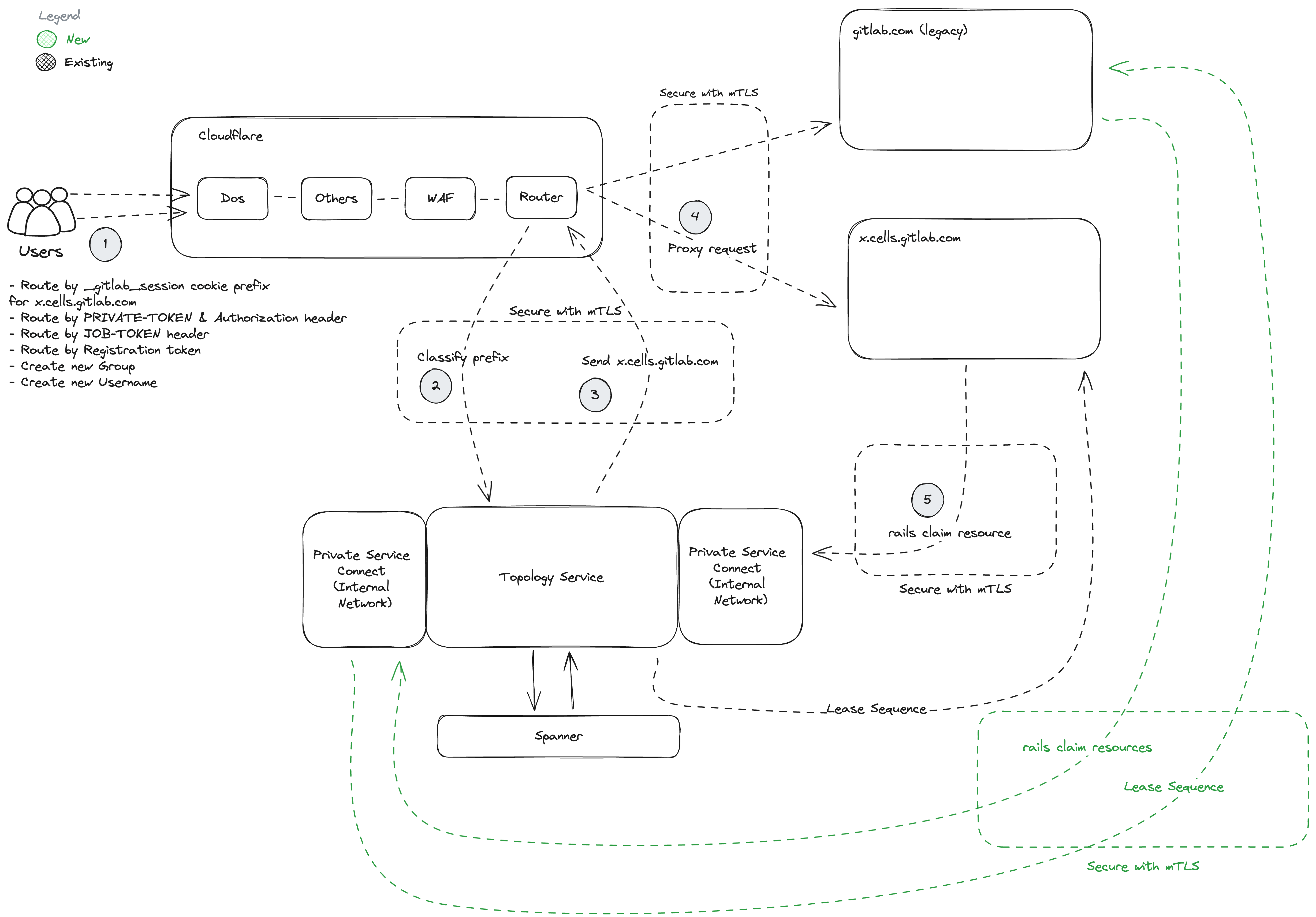
Details:
Phase 7: Cell Initialization
Exit Criteria:
- TBD
Before/After:
Details:
Phase 8: Organization Onboarding
Exit Criteria:
- TBD
Before/After:
Details:
Phase 10: Production Readiness
Exit Criteria:
- Cell-Level Observability (Logs, Metrics, Alerts, Dashboard).
- Integration with existing Incident Management tooling.
- Compliance with GitLab.com security standards.
- Regional and Zonal Disaster Recovery capabilities.
- Operational tooling independence from GitLab.com/dev.gitlab.org availability.
- Centralized WAF management for GitLab.com domain.
- Cell-level Application Rate Limits with synchronization.
- Least-privileged access implementation with SRE escalation path.
- Progressive rollout of infrastructure changes across Cells with rollback support.
- Progressive deployment capabilities across Legacy Cell and Cells with rollback support.
- Support for toggling Feature Flags across Legacy Cell and Cells.
Dependencies:
- Phase 1: GCP organizations, Ring definition exists.
Before/After:
Details:
Questions
-
How will we onboard users to an Organization on additional Cells?
An Admin will perform the following tasks:
- Create an Organization on the additional cell.
- Create a new user with the Owner role in the Organization.
- Remove the Admin from the Organization. Optional, depending on feature set.
- The new Owner will import data for this group. This would create users, add them to the groups/projects, and add them to the Organization.
-
How do we register new users for the existing Organization on an additional Cell?
The standard group and project invite flows can be used. This means a user with adequate permissions can invite users by email to any group or project in the Organization. After the user registers they will be added to the group or project and the Organization.
-
How would users log in?
- UI: The login to Organizations would be scoped to the Organization:
https://<GITLAB_DOMAIN>/users/sign_in?organization=gitlab-inc. - SAML:
https://<GITLAB_DOMAIN>/users/auth/saml/callbackwould receive?organization=gitlab-incwhich would be routed to the correct Cell. - This would require using the dynamic routing method with a list of Organizations available using a solution with high availability.
- UI: The login to Organizations would be scoped to the Organization:
-
How do we add a new table if it is initially deployed on additional Cell?
The Topology Service is ensuring uniqueness of sequences, so it needs to have
sequence. -
Is Container Registry cluster-wide or cell-local?
The Container Registry can be run Cell-local, and if we follow the secret-based routing, it can follow the same model for filtering. We would have to ensure that the JWT token signed by GitLab is in a form that can be statically routed by the routing layer.
-
Are GitLab Pages cluster-wide or Cell-local?
GitLab Pages was determined to be non-essential for Cells 1.0, so we would not support them for Cells 1.0. The discussion about this can be found here.
If GitLab Pages are meant to support the
.gitlab.iodomain:- GitLab Pages need to be run as a single service that is not run as part of a Cell.
- Because GitLab Pages use the API we need to make them routable.
- Similar to
routes, claimpages_domainon the Topology Service - Implement dynamic classification in the routing service, based on a classification key.
- Cons: This adds another table that has to be kept unique cluster-wide.
Alternatively:
- Run GitLab Pages in a Cell, but provide a separate domain.
- Custom domains would use the separate domain.
- Cons: This creates a problem with having to manage a domain per Cell.
- Cons: We expose Cells to users.
-
Should we use a static secret for the internal endpoint or JWT?
To be defined. The static secret is used for simplicity of the presented solution.
-
How do we handle SSH cloning?
This is a separate problem tangential to routing, which is intentionally not solved by this proposal. The problems associated with SSH cloning are:
- We need to validate a user public key to identify the Cell holding it.
- We need to ensure uniqueness of public keys across the cluster.
-
Are there other cluster-wide unique constraints?
- Authorized keys
- GPG keys
- Custom e-mails
- Pages domains
- TBD
-
How do we synchronize cluster-wide tables, such as broadcast messages or application settings?
We would very likely take a naive approach: expose those information using API, and synchronize it periodically. Tables likely to be made synchronized are:
- Application Settings
- Broadcast Messages
- TBD
-
How do we dogfood this work?
To be defined.
-
How do we manage admin accounts?
Since we don’t yet synchronize across the cluster, admin accounts would have to be provided per Cell. This might be solved by GitLab Dedicated already?
-
How are secrets are generated?
The Cell prefix is used to generate a secret in a way that encodes the prefix. The prefix is added to the generated secret. Example:
- GitLab Runner Tokens are generated in the form:
glrt-2CR8_XYZ - For Cell prefix:
secrets_prefix: kPptz - We would generate Runner tokens in the form:
glrt-kPptz_2CR8_XYZ
- GitLab Runner Tokens are generated in the form:
-
Why secrets-based routing instead of path-based routing?
Cells 1.0 are meant to provide a first approximation of the architecture allowing to deploy a multi-tenant and multi-Cell solution quickly. Solving path-based routing requires significant effort:
- Prefixing all existing routes with
/org/<org-name>/-/will require a deliberate choice how to handle ambiguous or Cell-local or cluster-wide routes, such as/api/v4/jobs/request. Changing routes also introduces breaking changes for all users that we would migrate. - Making all existing routes routable would be a significant effort to fix
for routes like
/-/autocomplete/usersand likely a multi-year effort. Some preliminary analysis how many routes are already classified can be found in this comment. - In each case the routing service needs to be able to dynamically classify existing routes based on some defined criteria, requiring significant development effort, and increasing the dependency on the Topology Service.
By following secret-based routing we can cut a lot of initial complexity, which allows us to make the best decision at a later point:
- The injected prefix is a temporary measure to have a static routing mechanism.
- We will have to implement dynamic classification anyway at a later point.
- We can figure out what is the best way to approach path-based routing after Cells 1.0.
- Prefixing all existing routes with
-
What about data migration between Cells?
Cells 1.0 is targeted towards internal customers. Migrating existing customers, and onboarding new customers is a big undertaking on its own:
- Customers to be migrated need to opt into the Organization model first.
- New Customers are not willing to have missing features
- We expect most of the isolation features to work.
- We have to transparently move data from the source Cell to the target Cell. Initially we would follow a model of Cell split. We would clone the Cell and mark where the given record is located.
Existing customers could still be migrated onto a Cells 1.0, but it would require to use import/export features similar to how we migrate customers from GitLab.com to Dedicated. As a result, not all information would be migrated. For example, the current project import/export does neither migrate CI traces, nor job artefacts.
-
Is secret-based routing a problem?
To be determined.
-
How would we synchronize
usersacross Cells?We build out-of-band replication. We have yet to define if this would be better to do with an
APIthat is part of Rails, or using the Dedicated service. However, using Rails would likely be the simplest and most reliable solution, because the application knows the expected data structure.Following the above proposal we would expose
usersand likely all adjacent tables usingAPI:/api/v4/internal/cells/users/:id. The API would serialize theuserstable into aprotobufdata model. This information would be fetched by another Cell that would synchronize user entries. -
How would the Cell find users or projects?
The Cell would use Classify Service of Topology Service.
-
Would the User Profile be public if created for enterprise customer?
No. Users created on another Cell in a given Organization would be limited to this Organization only. The User Profile would be available as long as you are logged in.
-
What is the resiliency of a Topology Service exposing cluster-wide API?
The API would be responsible for ensuring uniqueness of: User, Groups, Projects, Organizations, SSH keys, Pages domains, e-mails. The API would also be responsible for classifying a classification key for the routing service. We need to ensure that the Topology Service cluster-wide API is highly available.
-
How can instance-wide CI runners be configured on the new cells?
To be defined.
-
Why not use FQDN (
mycorp.gitlab.comormygitlab.mycorp.com) instead?We want the
gitlab.comto feel like a single application, regardless how many organizations you interact with. This means that we want to share users, and possibly some data between organizations at later point. Following model ofmycorp.gitlab.comormygitlab.mycorp.comcreates a feel of a strong isolation between instances, and different perception of how system operates compared to how we the system to actually behaves. -
Are feature-flags cell-local or cluster-wide?
To be defined.
-
How the Cells 1.0 differ to GitLab Dedicated?
- The GitLab Dedicated is a single-tenant hosted solution provided by GitLab Inc. to serve a single customer under a custom domain.
- The Cellular architecture is meant to be multi-tenant solution using
gitlab.comdomain. - The GitLab Dedicated by design has all resources separate between tenants.
- The Cellular architecture does share resources between tenants to achieve greater operational efficiency and lower cost.
-
Why the
Organization is private, and cannot be made publicin Cells 1.0?-
Private organizations on Cells do not require any data sharing or isolation as this is achieved by the current system.
- We don’t have to do extensive work to isolate organizations yet.
-
Routing is simpler since we anticipate all requests to be authenticated, making them easier to route.
- We don’t have to “fix” routes to make them sharded yet.
-
-
Why not to prefix all endpoints with the
relative_pathfor all organizations?This breaks the main contract of what we want to achieve:
- Migration to use organizations is seamless.
- We do not want to break existing user workflows if user migrates their groups to organization, or when we migrate the organization to another Cell.
- For the following reason this is why we don’t want to force particular paths, or use of subdomains.
- If we choose the path to force to use
relative_pathit would break all cell-wide endpoints This seems to be longer and more complex that approaching this by making existing to be shared. - If we choose to fix existing not sharded can be made at later point we will achieve much better API consistency, and likely much less amount of the work.
-
Why not use subdomains, like
mycorp.gitlab.com?Reasons to avoid using DNS for routing:
- Risks setting an expectation of full isolation, which is not the case.
- Care must be taken to prevent security issues with cookies leaking across subdomains.
- Complicates working across Organizations, with changing hostnames. and a requirement to pass full hostname in all links.
- Complicates integrations and API interactions, as the URL and host will change based on the organization.
- We will need to build a common login service, which will redirect users to a valid organization/URL.
- Increased risk of naming collisions with higher impact. For example different divisions or organizations across a large enterprise, or companies with similar names.
-
What about Geo support?
The Geo support is out of scope of Cells 1.0. However, it is fair to assume the following:
- Geo is per-Cell.
- Routing Service can direct to Geo replica of the Cell (if it knows it).
- We might have many routing services in many regions.
-
Are cluster-wide tables available to all cells?
No, cluster-wide tables are stored in a Cell-local database. However, we will determine synchronization of cluster-wide tables on a case by case basis.
-
How can I adapt a feature to be compatible with Cells?
Many groups have questions about how to adapt a feature for Cell. This especially applies if a feature is available at the instance level, or can be used across groups.
Here are some strategies for evolving a thing for Cells 1.0:
- Leave the feature unchanged. For example, admins / users will have to create an account per cell.
- Disable the feature for Cells 1.0.
- For critical cases, move the feature to cluster-wide level.
For example, users can sign in at a single location,
https://gitlab.com/users/sign_in.
In many cases, it is not yet necessary to re-implement an instance-wide feature to work on a cluster-wide level. This is because for Cells 1.0, the net effect of only allowing private visibility and new users mean that we can defer this until Cells 1.5.
ced19998)
