Data Insights Platform Querying API
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| accepted |
rob.hunt
|
ahegyi
|
lfarina8
nicholasklick
|
group platform insights | 2025-02-27 |
Summary
The Data Insights Platform (DIP) is a unified abstraction to ingest, process, persist & query analytical data streams generated across GitLab, enabling our ability to compute business insights across the product.
A part of this work, that needs further definition, is being able to query the analytical data once the data is processed and persisted in the DIP. The querying API must:
- Be easy for customers to use and moves the complexity of interacting with different data tables away from the API, and into the backend service.
- Be consistent for customers to easily identify what data is available, what properties that data has, and how they can interact with it.
This is important because of the current confusion with GitLab APIs in general. The problem we face is that many of the GitLab GraphQL and REST APIs are inconsistent, contributing to the confusion our customers face when interacting with GitLab, and we must avoid compounding that further.
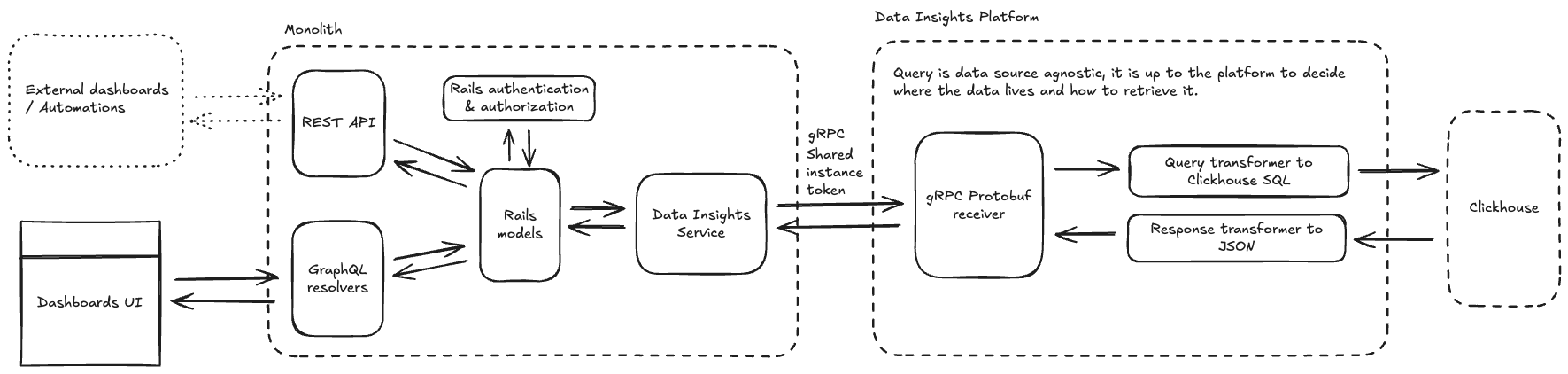
There will be two aspects of the overall querying architecture. The first part, the customers communication with the DIP through our existing GraphQL and REST APIs. The second part, the GitLab rails application’s (the Monolith) communication with the DIP through the Data Insights Service.
This proposal references the first part, but is focused on implementing the second.
Goals
- The querying API must support the ClickHouse exporter
- Although we have plans to support alternative exporters, our core initial goal is to work in conjunction with Siphon to collate and analyse GitLab data, which will be stored in ClickHouse tables.
- Consistent API interface
- We’ve had issues in the past with our APIs not being consistent in the type of data being available, and filtering options. This has led to a more confusing user experience.
- Difficult to accomplish, but we must develop an API which allows different data types and filtering options, without dramatically changing how the API request should be made or handled.
- Provide support and clear documented instructions on how other GitLab teams can integrate their GraphQL and REST API endpoints that leverage ClickHouse into the DIP querying API.
- Keep complexity away from the end-user APIs
- The DIP will be handling a wide range of data types and data sources, all being converged into one platform for fully formed analyses. We don’t want this complexity to be passed onto the end-user APIs.
- We need to keep the API straightforward to use; with clear documentation. The user should be informed about the data available to them. They should not be required to know which database or table to use.
- Authentication and authorization
- The data being collected by the DIP will contain a mix of data privacy categories. We need to ensure that any data being queried is only accessible to those with the correct authentication and authorization. Data outside the purview of the requestor must in no way be accessible to them.
- Data classification will be determined by the Data Catalog in Atlan.
Non-Goals
- Support for other data sources, such as Snowflake, for this initial phase.
- Integrating all other GraphQL and REST API calls that leverage ClickHouse that aren’t owned by Monitor/Platform Insights is out of scope. This work is best executed by the team with domain expertise and it is not scalable for Monitor/Platform Insights to do so for every team. Support and documentation will be provided to enable teams to integrate their endpoints into the DIP.
Historical context
Existing APIs
We have three APIs that were already developed to work with analytical data within their own ClickHouse databases. The APIs were developed independently, and therefore are not compatible with each other in terms of data available, how we interact with the APIs, or how the data is formatted.
The observability and cube API’s are not planned to be integral to the querying API, but rather are here for historical context and learning from our experiences with them.
Observability API
Written in Go, the Observability API is REST-based and is used to retrieve data from the GitLab Observability Backend (GOB). The data is stored in a separate ClickHouse database and formatted to work with the OTel format.
The API uses Cloud Connector to authenticate requests and is restricted to singular project requests; rather than being able to span multiple projects within a group.
Users can read and write data directly to GOB through the APIs various endpoints:
- Read:
get api/v4/projects/[PROJECT_ID]/observability/v1/analyticsget api/v4/projects/[PROJECT_ID]/observability/v1/tracesget api/v4/projects/[PROJECT_ID]/observability/v1/servicesget api/v4/projects/[PROJECT_ID]/observability/v1/metricsget api/v4/projects/[PROJECT_ID]/observability/v1/logs
- Write:
post api/v4/projects/[PROJECT_ID]/observability/v1/tracespost api/v4/projects/[PROJECT_ID]/observability/v1/metricspost api/v4/projects/[PROJECT_ID]/observability/v1/logs
This API is not sufficiently documented and requires reading the code within GOB or GitLab to understand what data to expect, and what parameters can be used. However, this is expected as O11y has been withdrawn as a customer offering whilst we work on the DIP.
Cube API
Product Analytics uses Cube to act as a query layer for communicating with the Analytics Stack which uses ClickHouse under-the-hood to store analytics data.
Requests are sent to the Cube proxy which is used to validate the request using Rails authentication, prevent direct API requests to Cube from the frontend, handle any errors, and also do any data transformations needed. The only data transformation currently done is to fill empty data points within a given date range. This transformation is something that can be done using ClickHouse directly, but this isn’t supported by Cube and the proposal to add support was rejected by the Cube core team.
Cube uses JSON Web Tokens (JWTs) to define security context within a multi-tenant environment, which is another reason why we are using the proxy. We use Rails authentication to determine if the requestor has permission to get analytics data for the project, then build the JWT with the correct project permissions, which then allows the requestor to retrieve the data from Cube.
From the Cube proxy, Cube will use the pre-defined schemas to generate ClickHouse queries and return the data. Cube provides a consistent query language for users to be able to define queries and return it in a consistent format, with a lot of pre-built filters and formatted data types.
The Cube API is a read-only REST API with the following endpoints:
get v1/meta- Used to generate the list of possible fields, data types, and filtering options for the Data Explorer in conjunction with the Cube data source.
post v1/load- Used to retrieve data for the query provided, the core endpoint for data retrieval.
The API is documented within our REST API documentation. This will need deprecating or removing when we decide to move onto alternative approaches other than Cube.
We have had issues with Cube supporting more advanced features without using their Cube store (we had concerns around storing RED data in their solution). It also doesn’t support more advanced features in ClickHouse, such as certain functions or pre-aggregations. As such, there has been a lot of discussion around moving away from Cube for some time.
Optimize
Optimize uses ClickHouse to help keep their aggregated queries for the Contributions, Value Stream, and AI Impact dashboards performant.
For Contributions, data from Postgres is aggregated and added to ClickHouse every 3 minutes. Upon data retrieval, a combination of ClickHouse data and specific Postgres data is used to populate the Contributions dashboard.
Value Stream and AI Impact only use ClickHouse for their data. AI Impact updates its data every 5 minutes rather than the 3 minutes for Contributions and Value stream.
All three dashboards use GraphQL for the frontend to query the Monolith, and the GraphQL resolvers directly call the ClickHouse database using the clickhouse_client gem package maintained by the Optimize team.
The following GraphQL types are used:
GroupValueStreamAnalyticsFlowMetricsProjectValueStreamAnalyticsFlowMetricsGroupValueStreamDashboardUsageOverviewProjectValueStreamDashboardUsageOverviewGroupValueStreamsProjectValueStreamsGroupContributionsGroupAiMetricsProjectAiMetricsGroupAiUserMetricsProjectAiUserMetricsaiUsageData(group)aiUsageData(project)
GLQL
The GitLab Query Language (GLQL) is an initiative started within the Plan stage to develop a single query language for our customers to interact with their GitLab data.
GLQL is currently built around being used within Markdown blocks, using YAML as it’s base language. It only supports issues at the time of writing and is specifically developed for use within:
- Wikis (group and project)
- Epics and epic comments
- Issue and issue comments
- Merge requests and merge request comments
- Work items (tasks, OKRs, epics with the new look) and work item comments
The first goal of GLQL is to allow customers to generate auto-updating lists of issues to help them with collaboration and planning. In the medium-term, the Plan stage plans to add support for listing merge requests, epics, and other work items.
Longer-term, GLQL could be the final piece in the data platform puzzle, providing a consistent query format for our customers to interact with all GitLab data, not just Plan-specific data. This would include data from the data platform. However, internal resource limitations, mean that this is a long-term ideal rather than something that could be actioned in FY26.
GLQL is built using Rust. The code is compiled into a WASM frontend module. The module parses the GLQL query before generating the resulting GraphQL query as its output. The generated GraphQL query is then used by the frontend as it usually would to request the resulting data.
Querying API preface
We need to remove the complexity of how the DIP works from the API consumer. Therefore, we must make a querying API which provides a consistent interface for the API consumer which ignores where the data came from, only that this data exists.
Discarded solutions
A few potential solutions were considered before being discarded as unworkable, these include:
- Reusing the existing API implementations
- Existing implementations rely on external dependencies, which goes against our requirements for the DIP.
- Product Analytics and Observability will be removed as an offering, therefore the existing implementations are not going to be used.
- Integrating directly with GLQL
- Written in Rust (reasoning for Rust is documented), which has limited knowledge within the Monitor stage, and would require additional steps to add to the DIP which is primarily Go-based.
- The GLQL roadmap is Plan stage focused, integrating directly would detract from that roadmap.
Of course, we can use the existing APIs as a learning opportunity for developing the new API.
Chosen solution
We will use the existing GraphQL and REST API infrastructure for UI/customer communication, with a Protobuf over gRPC API for communication between the Monolith and the DIP.
Later, we will augment these APIs with GLQL integration. GLQL has been built with integrating with existing APIs in mind, whereby the end-user uses GLQL to build their query, and GLQL transforms the request into the underlying API call, so we can go ahead and build our own API, and integrate into the existing GLQL infrastructure later.
We also wouldn’t need to worry about delaying Plan’s existing roadmap, as we can work with them to find a time to integrate later when GLQL is in GA.
API Structure
We have two existing GitLab API’s in GraphQL and REST that will need to communicate with the Monolith’s DIP service through rails models.
We will need to create a new Protobuf-over-gRPC API for the Monoliths DIP service to communicate with the DIP itself, and translate the response into something that the Monolith will understand.
The GraphQL and REST API’s within the Monolith will not be designed by the team working on the DIP. These API’s will be owned by the teams that own the feature. The team working on the DIP will only own and support the integration with the DIP itself.
GraphQL format
The GraphQL API will use the existing GitLab GraphQL service. Therefore, we should follow all the relevant guidelines to developing a new GraphQL endpoint within the service.
The GraphQL API’s structure will be determined by the team building the feature. The DIP will not dictate how this API is structured. It is up to the team building the feature to transform the GraphQL request to something that the DIP will understand, and handle the response from the DIP to be returned to the requestor.
We must document how we expect the GraphQL resolvers interact with the DIP service, in terms of expected request and response.
REST format
The REST API will use the existing GitLab REST API. Therefore, we should follow all the relevant guidelines to developing a new REST endpoint within the existing REST API framework.
The REST API’s structure will be determined by the team building the feature. The DIP will not dictate how this API is structured. It is up to the team building the feature to transform the REST request to something that the DIP will understand, and handle the response from the DIP to be returned to the requestor.
We must document how we expect the REST handlers interact with the DIP service, in terms of expected request and response.
Due to the nature of the queries we expect to receive, with extensive filtering options such as filtering by specific projects or users, as well as the potential for queries to contain PII data, the REST endpoints must use POST to send queries to the REST endpoint. Using POST will help us avoid URL length limits (roughly 2,000 characters), and prevent PII data being stored in GET query logs.
POST queries must have size limits applied to the parameters given. This is to prevent users from attempting excessive data requests, such as all MRs from 100K users.
Protobuf format
The Protobuf API must be written using the binary format. Using ProtoJSON would work, but is far less performant, and uses a lot more resources.
The API must follow Protobuf style standards and best practices. It must also make sure that all requests do not exceed the limits outlined by Protobuf. If a response is expected to exceed these limits, it must be made into a stream and sent to the requestor in chunks.
For any API changes, .proto files must be generated for both Go and Rails. These must then be added to the DIP and the Monolith respectively.
Versioning
We must follow the versioning guidelines for GitLab’s GraphQL and REST API.
For gRPC, we must version the packages within Go. This will version the gRPC call itself, and allow us to manage version upgrades. For best practice suggestions, Microsoft has a good guide focused on .NET, but is applicable for other languages.
For flagging features within gRPC we must follow the same standard as Gitaly but prefix flags with data_insights_* instead.
Protobuf is designed to handle versioning automatically by following their best practices. We must not re-use field numbers or field names, any fields removed in future versions must be reserved.
Pagination
For performance reasons, any non-aggregate queries must follow Keyset-based pagination. This approach exposes a link (or cursor) to the next page rather than using page IDs. Their should be a cursor for the next and previous pages (when applicable), using column data to generate the appropriate cursor. We do this already for GraphQL.
Aggregate queries are any queries that look to review a small sub-set of data points over a period of time, rather than listing individual rows within the database. In other words, the difference between showing a visualization of merged MRs over time, rather than listing merged MRs in a table.
Aggregate queries must be limited by a restricting factor like a timestamp, but due to their nature can’t be paginated. These queries must also be tagged or labelled to note that these are aggregations.
ClickHouse doesn’t leverage “traditional” primary keys which means we need to rely on the sorting option to define the next group of items in the query when generating the pagination link. For example, if a user sorts by descending the last updated timestamp, the generated pagination link would filter the next query to be from the previous queries oldest last updated timestamp. In the event that a query doesn’t define a sorting option, we must set a default for each endpoint.
Automated schema generation
To keep the API schema up-to-date as efficiently as possible, we should look at automating the schema generation and documentation for the Protobuf API. This could be done on creation of a new version, deployment, or even after every merge. This should then update the relevant documentation.
Example queries
These queries are for example purposes only. They do not reflect what might actually be written, nor should they limit what we end up building during implementation.
Group Contributions
GraphQL query
query getContributionsData($fullPath: ID!, $startDate: ISO8601Date!, $endDate: ISO8601Date!, $nextPageCursor: String = "", $first: Int) {
group(fullPath: $fullPath) {
id
contributions(
from: $startDate
to: $endDate
first: $first
after: $nextPageCursor
) {
nodes {
repoPushed
mergeRequestsCreated
mergeRequestsMerged
mergeRequestsClosed
mergeRequestsApproved
issuesCreated
issuesClosed
totalEvents
user {
id
name
webUrl
}
}
pageInfo {
endCursor
hasNextPage
}
}
}
}
GraphQL variables
"variables": {
"endDate": "2025-02-13",
"fullPath": "gitlab-org",
"nextPageCursor": "",
"startDate": "2025-02-06"
}
Protobuf definition
// Editions version of proto3 file
edition = "2023";
package gitlab.group.contributions.v1;
option go_package = "gitlab.com/api/group/contributions/v1";
import "google/protobuf/timestamp.proto";
service GroupContributionsService {
// GetGroupContributions retrieves contribution data for a group within a date range
rpc GetGroupContributions(GetGroupContributionsRequest) returns (GetGroupContributionsResponse) {}
}
// Request message for GetGroupContributions
message GetGroupContributionsRequest {
// Full path of the group (e.g., "gitlab-org")
string full_path = 1;
// Start date for contributions in ISO8601 format (YYYY-MM-DD)
string start_date = 2;
// End date for contributions in ISO8601 format (YYYY-MM-DD)
string end_date = 3;
// Pagination: next page continuation token from previous response
optional string next_token = 4;
// Pagination: previous page continuation token from previous response
optional string previous_token = 5;
// Pagination: number of results to return
optional int32 page_size = 6;
}
// Response message for GetGroupContributions
message GetGroupContributionsResponse {
// Group info
Group group = 1;
// Pagination information
PageInfo page_info = 2;
}
// Group represents a GitLab group
message Group {
// Group ID
string id = 1;
// Contributions within the specified date range
ContributionConnection contributions = 2;
}
// ContributionConnection represents a paginated collection of contributions
message ContributionConnection {
// List of contribution nodes
repeated ContributionNode nodes = 1;
// Pagination information
PageInfo page_info = 2;
}
// ContributionNode represents a single user's contributions
message ContributionNode {
// Number of repository pushes
int32 repo_pushed = 1;
// Number of merge requests created
int32 merge_requests_created = 2;
// Number of merge requests merged
int32 merge_requests_merged = 3;
// Number of merge requests closed
int32 merge_requests_closed = 4;
// Number of merge requests approved
int32 merge_requests_approved = 5;
// Number of issues created
int32 issues_created = 6;
// Number of issues closed
int32 issues_closed = 7;
// Total number of events
int32 total_events = 8;
// User information
User user = 9;
}
// User represents a GitLab user
message User {
// User ID
string id = 1;
// User's name
string name = 2;
// URL to user's profile
string web_url = 3;
}
// PageInfo provides pagination metadata
message PageInfo {
// Token that can be used to fetch the next page
// When empty or missing, there are no more pages after this one
optional string next_token = 1;
// Token that can be used to fetch the previous page
// When empty or missing, there are no pages before this one
optional string previous_token = 2;
}
gRPC request
# Step 1: Add required gems to your Gemfile
# Gemfile
# gem 'grpc'
# gem 'google-protobuf'
# Step 2: Generate Ruby code from your .proto file using protoc
# You'd run this command in your terminal:
# protoc --ruby_out=lib/protos --grpc_ruby_out=lib/protos -I protos protos/group_contributions.proto
# Step 3: Create a client wrapper class in app/services/group_contributions_client.rb
module Services
class GroupContributionsClient
def initialize(host = 'localhost:50051', bearer_token)
# Use TLS/SSL for secure connection
ssl_creds = GRPC::Core::ChannelCredentials.new
auth_creds = bearer_token_credentials(bearer_token)
credentials = ssl_creds.compose(auth_creds)
@stub = Gitlab::Group::Contributions::V1::GroupContributionsService::Stub.new(
host,
credentials
)
end
def get_group_contributions(full_path, start_date, end_date, next_token = nil, previous_token = nil, page_size = 50)
request = Gitlab::Group::Contributions::V1::GetGroupContributionsRequest.new(
full_path: full_path,
start_date: start_date,
end_date: end_date,
next_token: next_token,
previous_token: previous_token,
page_size: page_size
)
@stub.get_group_contributions(request)
end
private
def bearer_token_credentials(token)
proc_metadata_generator = proc { { 'authorization' => "Bearer #{token}" } }
GRPC::Core::CallCredentials.new(proc_metadata_generator)
end
end
end
# Step 4: Use the client in your controller
class ContributionsController < ApplicationController
def index
client = Services::GroupContributionsClient.new(
ENV['CONTRIBUTIONS_GRPC_HOST'],
ENV['CONTRIBUTIONS_API_TOKEN']
)
# Determine which token to use based on navigation direction
next_token = params[:next_token]
previous_token = params[:previous_token]
@response = client.get_group_contributions(
params[:group_path],
params[:start_date],
params[:end_date],
next_token,
previous_token,
params[:page_size] || 50
)
# Transform gRPC response to a format suitable for your views
@contributions = @response.group.contributions.nodes.map do |node|
{
user: {
id: node.user.id,
name: node.user.name,
url: node.user.web_url
},
metrics: {
repo_pushes: node.repo_pushed,
mr_created: node.merge_requests_created,
mr_merged: node.merge_requests_merged,
mr_closed: node.merge_requests_closed,
mr_approved: node.merge_requests_approved,
issues_created: node.issues_created,
issues_closed: node.issues_closed,
total_events: node.total_events
}
}
end
@pagination = {
next_token: @response.page_info.next_token,
previous_token: @response.page_info.previous_token
}
respond_to do |format|
format.html
format.json { render json: { contributions: @contributions, pagination: @pagination } }
end
end
end
gRPC response
// SERVER IMPLEMENTATION
package main
import (
"context"
"log"
"net"
pb "gitlab.com/api/group/contributions/v1"
"google.golang.org/grpc"
)
type groupContributionsServer struct {
pb.UnimplementedGroupContributionsServiceServer
}
func (s *groupContributionsServer) GetGroupContributions(ctx context.Context, req *pb.GetGroupContributionsRequest) (*pb.GetGroupContributionsResponse, error) {
// In a real implementation, you would:
// 1. Parse dates
// 2. Fetch data from database
// 3. Format the response
// Mock implementation for example
return &pb.GetGroupContributionsResponse{
Group: &pb.Group{
Id: "gid://gitlab/Group/9970",
Contributions: &pb.ContributionConnection{
Nodes: []*pb.ContributionNode{
{
RepoPushed: 5,
MergeRequestsCreated: 3,
MergeRequestsMerged: 2,
MergeRequestsClosed: 1,
MergeRequestsApproved: 4,
IssuesCreated: 2,
IssuesClosed: 1,
TotalEvents: 18,
User: &pb.User{
Id: "gid://gitlab/User/123456",
Name: "Jane Developer",
WebUrl: "https://gitlab.com/jane_developer",
},
},
// Additional nodes would be added here
},
PageInfo: &pb.PageInfo{
NextToken: "next_token_xyz",
PreviousToken: "", // Empty because this is the first page
},
},
},
PageInfo: &pb.PageInfo{
NextToken: "next_token_xyz",
PreviousToken: "", // Empty because this is the first page
},
}, nil
}
func main() {
lis, err := net.Listen("tcp", ":50051")
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
grpcServer := grpc.NewServer()
pb.RegisterGroupContributionsServiceServer(grpcServer, &groupContributionsServer{})
log.Println("Starting gRPC server on port 50051...")
if err := grpcServer.Serve(lis); err != nil {
log.Fatalf("failed to serve: %v", err)
}
}
// CLIENT IMPLEMENTATION
package main
import (
"context"
"log"
"time"
pb "gitlab.com/api/group/contributions/v1"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
func main() {
conn, err := grpc.Dial("localhost:50051", grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
client := pb.NewGroupContributionsServiceClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
// Example of a first page request
resp, err := client.GetGroupContributions(ctx, &pb.GetGroupContributionsRequest{
FullPath: "gitlab-org",
StartDate: "2025-02-06",
EndDate: "2025-02-13",
NextToken: "", // Empty for initial request
PreviousToken: "", // Empty for initial request
PageSize: 50
})
if err != nil {
log.Fatalf("could not get group contributions: %v", err)
}
// Process the response, e.g.:
log.Printf("Group ID: %s", resp.Group.Id)
log.Printf("Number of contributors: %d", len(resp.Group.Contributions.Nodes))
// Access pagination info
log.Printf("Next page token: %s", resp.PageInfo.NextToken)
log.Printf("Previous page token: %s", resp.PageInfo.PreviousToken)
log.Printf("Has next page: %v", resp.PageInfo.NextToken != "")
log.Printf("Has previous page: %v", resp.PageInfo.PreviousToken != "")
// Store tokens for navigation
nextPageToken := resp.PageInfo.NextToken
// Example of requesting the next page (if available)
if nextPageToken != "" {
nextPageResp, err := client.GetGroupContributions(ctx, &pb.GetGroupContributionsRequest{
FullPath: "gitlab-org",
StartDate: "2025-02-06",
EndDate: "2025-02-13",
NextToken: nextPageToken, // Use next token from previous response
PreviousToken: "", // Not needed when navigating forward
PageSize: 50
})
if err != nil {
log.Fatalf("could not get next page: %v", err)
}
// Process next page...
log.Printf("Next page - contributors: %d", len(nextPageResp.Group.Contributions.Nodes))
}
// Access individual contributions
for i, node := range resp.Group.Contributions.Nodes {
log.Printf("Contributor #%d: %s", i+1, node.User.Name)
log.Printf(" Total group events: %d", node.TotalEvents)
// And so on...
}
}
Example protobuf parameters
Group Contributions
datetimeBefore- Only accepts UTC, conversion to and from user’s timezone should be done by the API caller
- Formatted to ISO-8601
datetimeAfter- Only accepts UTC, conversion to and from user’s timezone should be done by the API caller
- Formatted to ISO-8601
fullPath- Path to the GitLab group/namespace/project
Response codes
The following response codes must be returned by the Protobuf API:
200 OK- On success response400 INVALID_ARGUMENT- When a query is malformed401 UNAUTHENTICATED- When a user is not authenticated403 PERMISSION_DENIED- When a user is authenticated but doesn’t have permission to query a particular resource404 NOT_FOUND- When a request is sent to an unknown endpoint429 RESOURCE_EXHAUSTED- When a request is trying to retrieve more data than the API can handle (querying all the data we have on every issue since time immemorial, for instance), or when rate limits are exceeded500 INTERNAL- When the server fails unexpectedly
Response bodies should not expose the infrastructure or internal schematics of the DIP. All responses should be sent to our Metrics and Logs. Any error responses returned to the client must have user-friendly responses explaining the cause of the error without giving internal details.
Authentication, authorization, and security
Requests made to the DIP must pass through the Monolith. The DIP will not be accessible through direct endpoints.
The Monolith will authenticate and authorize all requests for data as per the normal Monolith processes.
Since the DIP is used only for internal communication, and all requests are pre-authorized by the Monolith, the DIP will use a shared authentication token to communicate with the Monolith via gRPC, in the same way as Gitaly already does. We must have a way to rotate this shared authentication token. See the Gitaly rotation runbook for how we do this for .com.
All requests to and from DIP, including internal network requests, should be encrypted using TLS or other appropriate encryption methods. Any data stored within the data flow of the querying API must be encrypted at rest (caches for example).
Performance
To keep query times down, as well as to optimize our data retrieval in general, we will likely heavily leverage ClickHouse’s pre-aggregated Materialized Views (MVs) wherever possible. This approach moves complex joining of data away from when data is SELECTed to when it is INSERTed. ClickHouse tends to perform better with larger tables, compared to JOINs.
Due to the asynchronus nature of ClickHouse data merging, queries will likely need to use GROUP BY or FINAL to ensure the correctness of queried data.
Each resource must document in our docs any limits that must be applied to avoid excessive query times. The resource must validated that these limits are not exceeded by any given query. If a query attempts to exceed these limits, a 429 RESOURCE_EXHAUSTED error must be returned with the reason why. For instance, a resource can only support queries of up to 30 days, and a query requests 60 days.
Rate limiting and IP blocking
For the GraphQL and REST APIs, as these will run through the existing GitLab framework, we should leverage the existing rate limiting and IP blocking capabilities.
Rate limiting headers (RateLimit-*) must be returned on API requests for the frontend to manage/inform the user if queries are being slowed down, or if the customer is automating API requests. Requests exceeding the defined rate limit should return a 429 RESOURCE_EXHAUSTED status code.
For the gRPC API, rather than defining rate limits, it is recommended to use a concurrency limit instead. Ideally, this should be adaptive, automatically backing off requests when a specific data source is getting overloaded. Each limit should be customisable per data source, as each one will have different limitations.
Metrics and logs
We must make sure that the Protobuf API is integrated with our existing observability infrastructure. All logs should be sent to Kibana, whilst frontend GitLab usage errors and performance should be sent to Sentry.
Logs must not store unnecessary personally identifiable information, secrets, or keys. All new logging calls must be checked to make sure we’re not leaking information into our logs that we shouldn’t.
ClickHouse queries must be logged in a redacted format, replacing placeholders with a ?. Query logs must have a hash of the query for easy comparison and finding of similar queries.
Errors must contribute to our Error Budget, so we can monitor improvements over time.
We must investigate how we can closely integrate with our Internal Analytics to track usage. We will add metrics to the frontend GitLab usage, but integration with the DIP needs investigation to see if it is feasible, or if we need to design a secondary API for sending events (Service Ping or the Events Tracking API?).
Metrics must be sent to Prometheus for us to track (not exhaustive):
- API response times
- API uptimes
- Resource usages
- Slow queries
- Expensive queries
Pagination
As outlined above, we must use keyset-based pagination where possible. For aggregated queries we will need to return the full query, but we should be able to mitigate some of the performance concerns by building pre-defined MVs for aggregated queries and using our metrics to monitor this over time.
Docs
We must create a quick start guide explaining how to connect and use the Protobuf API. This documentation should be aimed at users with limited knowledge of the DIP. The documentation must clearly outline the flow of data and which teams are responsible for each part of the flow.
In conjunction with the automation of the schema, we should publish the schema details, with all restrictions and parameters, to docs.gitlab.com.
We must create a guide on how to create MV’s for a given resource, and how to use these within the DIP to improve query times and performance.
Considerations for .com/dedicated/cells/self-managed
This API’s queries will not span multiple cells. Each query must be scoped to an instance (admin users of self-managed intances only), organization, namespace, group or project.
One of the core requirements for the DIP is for it to be deployed as part of the GitLab instance, similar to Gitaly. Therefore, all our customers should have access to the DIP in full.
3b5d656b)
