Doing UX research in the AI space
As more teams are taking part in rapid prototyping activities to innovate within the Artificial Intelligence (AI) space, it’s natural to pause and ask yourself: What’s the problem this aims to solve?
It’s common that exciting break-through technologies lead to product innovations. However, this can result in teams presenting a technical solution that is looking for a user problem - instead of the other way around.
We need to make sure to keep users’ needs (and unmet needs) in mind while innovating. If we don’t do this, the risk is that we end up building powerful AI solutions that may not address identified user problems.
This page guides you on how to do UX research in the AI space, by including the user’s perspective throughout the design and development of AI solutions.
For how you should use AI in your UX research work, see AI usage in UX.
UX Researcher support
If you have an assigned UX Researcher in your stage: If you need UX Research support, connect with your assigned stage UX Researcher following the research prioritization process. Your AI-specific research topic will be prioritized against the other research projects already identified within their stage.
If you DON’T have an assigned UX Researcher in your stage: For those working in a stage group that doesn’t have a UX Researcher assigned, Nick Hertz is managing those research requests. The research prioritization process still applies and you can add your topic to this AI research-specific prioritization calculator after you have opened a research issue.
The guidelines
Guideline 1: Start with identifying and understanding user needs
AI solutions themselves won’t reveal the user problem they are meant to solve. To identify and understand user needs (and to determine if the AI solution is addressing a real user problem), there are different approaches you can take:
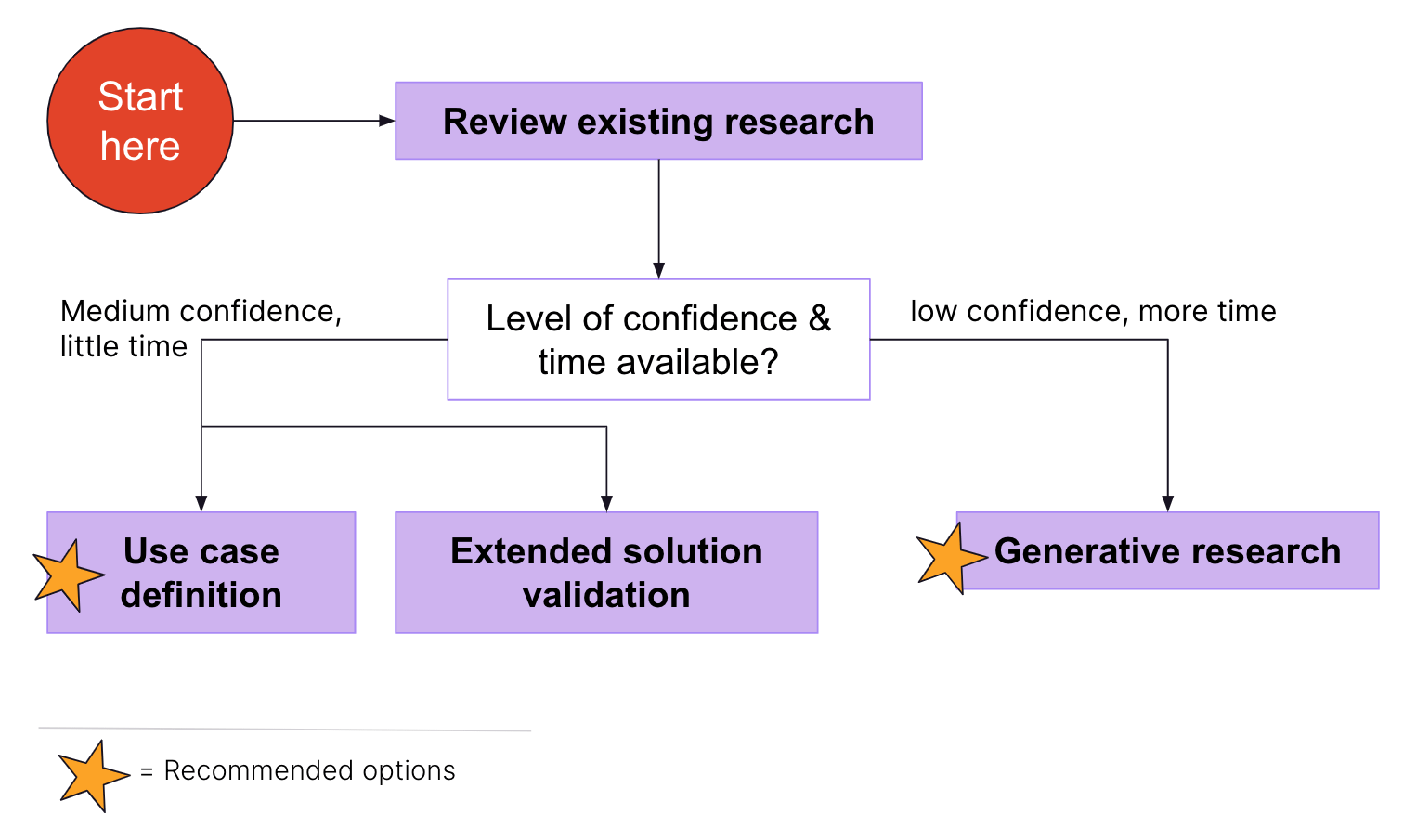
Review existing research
- Understand what research knowledge already exists. Dovetail and the UX Research Drive are good places to start as well as asking your assigned stage researcher. Reviewing what research exists outside of GitLab is valuable, too.
- If your review results in a medium or low level of confidence regarding users’ needs, the following options help with collecting additional data.
Use case definition (recommended option for medium level confidence)
- Use existing research and your domain expertise to formulate assumptions on the user problem you believe is being addressed with the AI solution. Use the following format to phrase the problem statement, which is aligned to how we write Jobs to be Done (JTBD):
- “When [circumstance a person is in when they want to accomplish something], I want to [something the person wants to accomplish].”
- Example: When I am on triage rotation and prioritizing business-critical risks, I want to review the most recent risk detected in my assets.
- Then, validate your problem statements through a quantitative online survey to understand:
- The frequency of users encountering this problem
- The importance of addressing the problem
- There are other parameters you can include in your survey, such as:
- How users currently solve the problem
- The difficulty of solving this problem today
- See this template for example questions. More example studies coming soon.
Extended solution validation
- Use solution validation-type studies to learn more about the users’ needs before they engage with the prototype or feature. To do so, add a few questions about their job tasks, workflows, tools, expectations, pain points etc. before participants start their tasks with the prototype (see this example). Moderated sessions are more suitable than unmoderated ones and are recommended.
Generative research (recommended option for low confidence)
- If you don’t have a high level of confidence or understanding of the problem statement or user needs, you will want to take the time to conduct generative research to learn more about a user group and their needs. While this approach takes more time, it provides deep insights into users’ needs, goals, and pain points that can be used to ideate on new solutions.
- It’s recommended to do this if you have the time. The output will provide a solid justification as to why the AI feature is important for users.
Guideline 2: Collect user feedback on your idea before building anything
Did you know that you can validate your future AI powered feature in parallel to the engineering team building it by using Wizard of Oz prototyping? Validating before the AI solution is available is a great way to capture users’ expectations and requirements early on. They can inform engineering efforts in training the AI.
Here are a few things to keep in mind when preparing the prototype:
- If your solution includes personalization, you should collect relevant user data for a more realistic experience in the prototype before the session takes place. Make sure users are informed about how their data is being used.
- Include “wrong” recommendations, too, as AI technology is probabilistic and won’t be accurate all the time (see Guideline 4). For example, let’s say you are evaluating a chatbot and participants want to ask questions about UX Research methods. Besides relevant responses to that topic, include some that are not connected to UX Research. You could vary how many “wrong” responses are given to understand what is still acceptable versus where users get frustrated and stop using it.
It may be tempting, but don’t ask users if they would use this AI feature. People are poor predictors of future behavior, so their answers won’t be accurate or useful for you. To get closer to understanding if people may use a solution, it’s best to understand:
- their problem or need, and
- how helpful the solution is with addressing those. In other words, does it provide value?
Guideline 3: Collect more than just usability feedback during AI prototype validation
Once an AI powered solution is available for validation, make sure to not only collect feedback on its usability, but also:
- Baseline data - on how users currently solve this problem. This allows us to assess the impact the AI solution may have and how helpful it is.
- On trust - If people trust the information provided by AI. If they don’t trust it, they won’t use it. Here are some example questions to consider:
- How much do you trust the [feature name, e.g. code suggestions] provided?
- Do you trust [feature name, e.g. code suggestions] with [task, e.g. providing correct code]? Why/Why not?
- On giving feedback - If they feel comfortable giving system feedback, e.g. when a code suggestion is not helpful. The AI improves based on user feedback, so it’s important they can do it. You can do this by including a task that focuses on giving feedback on a “wrong” recommendation and measure if they were successful doing it and how they felt about it.
- On attitudes towards third-party AI services - If your AI solution is powered by a third party (e.g. OpenAI), it’s important to understand if users are aware of the use of a third-party and their attitude towards it. This provides insights into users’ mental model (see Guideline 5) and impact on GitLab as a brand.
We are piloting a set of AI metrics and recommend including them in your solution validation.
To get robust feedback during solution validation, it’s recommended to collect at least three data points. As AI output varies, it’s not sufficient to rely on the first output only. You can do this by having three similar tasks to see how participants react to the AI’s responses in these three different scenarios.
Tip: Avoid asking the tempting “Would you use this?” question.
If you are maturing your AI feature towards Generally Available, take a look at the UX maturity requirements for further guidance on metrics and success criteria.
Guideline 4: Learn about the cost of errors that AI will make
AI will make mistakes due to their probabilistic nature. It’s important to understand how AI mistakes may affect users. Will certain mistakes result in turning users away from using it? Or using GitLab? Here’s what you can do:
- Plan for research activities to assess what mistakes are ok to do versus those that cause harm and need to be avoided at all cost.
- There may also be opportunities to include questions related to AI mistakes when conducting solution validation, e.g. When evaluating early prototypes (see Guidelines 2 and 3).
- Set up your prototype in a way that it includes “wrong” recommendations to capture how people react to AI mistakes.
Guideline 5: Plan ahead for longitudinal research
AI evolves as users engage with it over time. As a result, users’ mental models about how it works as they engage with it over time may change (it’s a continuous loop). To ensure we’re continuing to offer AI solutions of value, it’s important to understand how mental models change over time and evaluate the performance of AI solutions as use cases and users increase.
We are piloting a set of AI metrics that allow you to evaluate and track user’s experience with AI powered features over time.
AI User Experience Survey (Pilot)
We developed, and are currently piloting, a survey that contains a set of questions to evaluate AI powered features in terms of how well they are meeting user needs (not usability). This survey can be used to track a user’s experience with an AI powered feature over time.
The survey focuses on the following 8 constructs that we observed in a literature review and are captured in 11 survey questions.
- Accuracy: How accurate do users find our AI? How much effort is needed to get a meaningful response?
- Trustability/Fallibility: Do users trust GitLab’s AI?
- Value: Are we helping users to be faster and more productive? Are we helping users to learn new things? Do users perceive a benefit from using the AI powered feature?
- Control: Do users feel like they have control over how AI recommendations or actions are employed?
- Error handling: Are we enabling users to deal with the errors that AI produces?
- Guardrails: Have we built-in enough mindful friction into user iteractions with AI such that they are able to think critically about what AI is doing for them?
- Learnability: Are users able to quickly understand the AI powered feature?
- AI limits: Do users feel like they understand what the AI powered feature can and can’t do?
This survey is available for you to send to your participants who are working with AI features. If you want to use this survey, ask Anne Lasch or Erika Feldman for access to the Qualtrics project.
AI Usability Metric
To effectively evaluate the usability of our AI capabilities and track progress over time, please follow the instructions below:
What to measure
We have leveraged the existing Category Maturity Scorecard grading system and focused on 3 pieces of data to be measured for AI capabilities:
- Effectiveness (pass/fail)
- Efficiency (Single Ease Question)
- Satisfaction of the experience
These measures are lightweight, focusing on both the mechanics and the usability of the experience, and can be applied in either moderated or unmoderated tests.
When to measure
All AI / Duo capabilities should be assessed in any of the following scenarios:
- Before they become Generally Available (GA);
- When a significant change to the experience is introduced.
It’s at the designer and the product team’s discretion to regard a change as significant or not. And here are some examples to help you decide:
- Insignificant changes might be minor tweaks that enhance the interface but do not fundamentally change the user’s experience or the way they perform tasks / interact with the product. An example could be changing the colour of a button.
- Significant changes may significantly alter user behavior, and require users to adapt to a new way of interaction. An example could be an change to the information architecture of the product.
The full description of GA Scope and Definition of Done for Duo capabilities is here (internal access only).
How to measure
Follow the steps for running a Category Maturity Scorecard study, and only make the following adaptations:
- Recruit 5 external participants for the study;
- When a participant has completed a scenario, ask the Efficiency and Satisfaction questions only. You won’t need to ask the UMUX Lite question, as it doesn’t entirely pertain to our usablity focus.
Acceptance criteria
Similar to the Category Maturity Scorecard scoring (Figure 1), the calculated AI Usability score will be a number between 1.00 - 5.00. This is intended to give some granularity to the scores as regression/progression occurs. If need be, the score is translatable to an A-F grade scale.
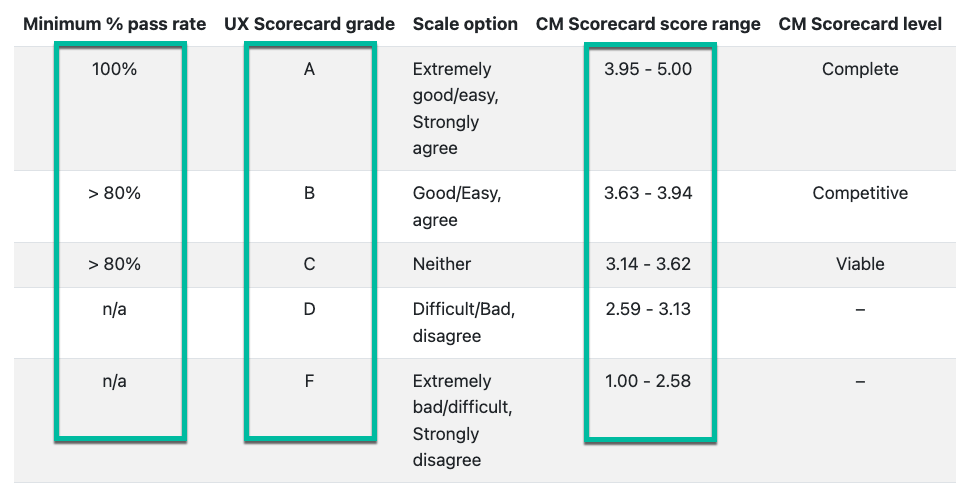 |
|---|
| Figure 1: Borrowing the existing scoring rubric from our Category Maturity Scorecard process |
A new Google Sheet is located here, which will calculate the AI Usability score for you.
The quality bar for AI capabilities is just as high as our other experiences within GitLab. That translates to
- a pass rate of 4/5 or 80%
- AND, a score range of 3.63-3.94, or a ‘B’ grade.
Other considerations
- Focus on user tasks that provide value to the user. JTBD may not exist yet in the space you’re working in. That’s ok; it shouldn’t be a blocker for AI usability testing.
- If you have 1 task failure, the failure (pass/fail) is documented, but their ratings aren’t documented; find a replacement participant to meet the minimum of 5 participants.
- If you have 2 task failures on the same task, stop testing that task. Understand what needs to be addressed, make adjustments, then start testing that task again.
- If the adjustments introduce significant changes to user experience, weigh confidence vs. risk to decide whether you should start afresh with 5 new participants.
- Testing AI experiences introduces new challenges to consider. For example, it’s important to be clear and accurate on the capabilities of what’s being shown to participants. This is to set the right kind of expectations. More details on this topic can be found in the Challenges of Testing AI Products section of this article.
References
- People + AI playbook by Google
- User research for machine learning systems - a case study
- Testing AI concepts in user research
- Human centered machine learning
- How to use AI in UX research at GitLab
4ff35e52)
