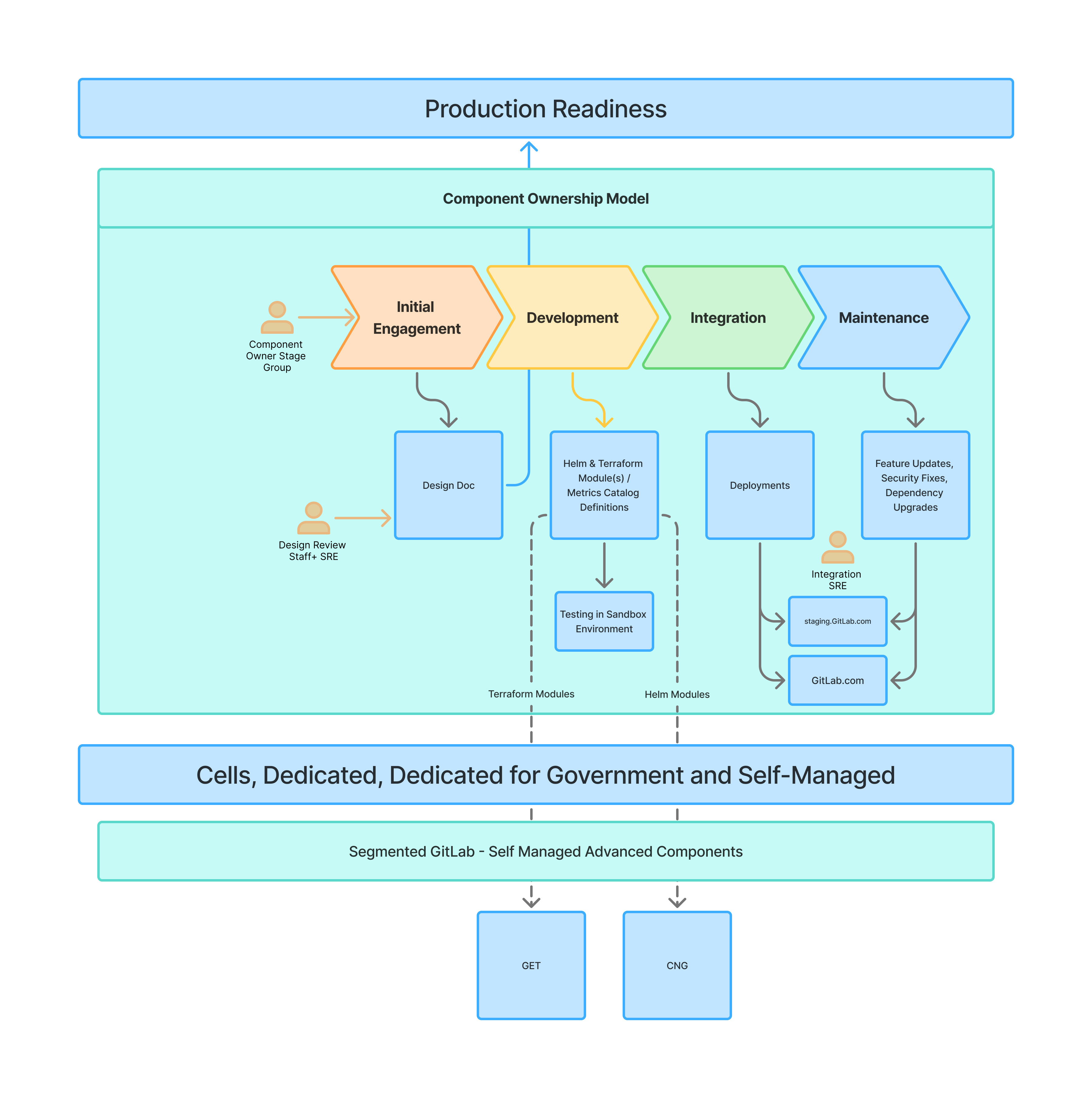
Component Ownership Model
A paved path for adding new Infrastructure Components to GitLab.com
Understanding the Ecosystem
The Component Ownership Model extends GitLab’s Production Readiness process with a focus on ownership, and best practices using a paved-path to Production.
It guides teams through bringing non-Runway infrastructure components online for GitLab.com. While focused on .com deployment, it ensures components remain compatible with GitLab’s broader deployment landscape: Dedicated, FedRAMP, Cells, and future Self-Managed offerings.
This model is part of a larger transformation. Other initiatives define the Self-Managed Foundation and Advanced (SMB/SMA) blueprint and the GitLab Infrastructure Platforms Review Process. The Component Ownership Model is focused on accelerating and unifying the approach taken for delivering new software components to GitLab.com in a way which aligns expectations, encourages ownership and reduces the need for manual (possibly slow) gatekeeping from Infrastructure Platforms department.
Relationship to Runway and the Production Readiness Process
This process is not a replacement for the Production Readiness process, but is intended to be an opinionated paved path designed to reduce the cycle time on Production Readiness.
This is similar to the goals of Runway. Selecting Runway is preferable to using this process, and should be used when possible.
Unfortunately, Runway does not yet support deployment of services into Self-Managed environments. In the case that a new component will require Self-Managed deployment, and until Runway supports Self-Managed, the Component Ownership Model is the next best option.
Compared to the previous engagement model, Component Ownership Model will allow teams to work with greater autonomy, faster cycle time, and greater alignment with Infrastructure.
Definitions
-
Component: A self-contained infrastructure-as-code module that provides specific functionality to GitLab.com. In this context, refers specifically to Helm charts or Terraform modules that define cloud resources or Kubernetes workloads. Components are versioned, tested, and are accessed through a well-defined interface.
-
Policy as Code: Infrastructure standards and requirements defined as machine-readable rules using tools like Open Policy Agent and
conftest, rather than written documentation. Policies are versioned, shared and distributed as OCI images. -
Semantic Versioning (SemVer): A versioning scheme using MAJOR.MINOR.PATCH format. See semver.org for detailed specification.
-
Component Owner: The Stage Group team or Infrastructure team responsible for a component from design through production operations, including on-call responsibilities, security updates, and ongoing maintenance.
-
Non-Runway Components: Infrastructure components that cannot use GitLab’s Runway platform due to specific requirements or constraints, necessitating the Component Ownership Model approach. For GitLab-application-components, the primary reason currently is the need the deploy on Self-Managed. Work for this is planned, but the feature is not yet available. Additionally, some services rely on infrastructure features not covered by Runway, such as advanced stateful Kubernetes features (e.g. Persistent Volumes, Stateful Sets, etc).
-
Integration Engineer: A Production Engineering team member who guides the integration of components into GitLab.com’s infrastructure, reviews implementation against design, and ensures policy compliance during the integration stage.
-
Reviewer SRE: A Staff+ Individual Contributor from Production Engineering who evaluates component designs during the engagement stage, focusing on scalability, operations, and architectural decisions.
-
Paved Path: An opinionated, standardized approach with pre-built tooling, templates, and automation that accelerates development while ensuring consistency and compliance.
-
config-mgmt: GitLab’s configuration management repository for infrastructure. Under the Component Ownership Model, components must NOT be added directly to this repository. -
k8s-workloads: GitLab’s Kubernetes workloads repositories. Likeconfig-mgmt, application components must be maintained separately and integrated as versioned dependencies. -
common-ci-tasks: A GitLab repository providing standardized CI components at https://gitlab.com/gitlab-com/gl-infra/common-ci-tasks that enforce policies, run tests, and automate deployments. -
Copier Templates: Project templates using the Copier tool that generate standardized project structures. Available at https://gitlab.com/gitlab-com/gl-infra/common-template-copier.
-
Metrics Catalog: GitLab’s centralized system for defining service metrics, which automatically generates dashboards and alerts. Components must integrate with this system for observability. It’s jsonnet dependencies can be imported from the runbooks repository.
-
Production Readiness: GitLab’s existing process for ensuring services meet operational requirements before production deployment. The Component Ownership Model extends and accelerates this process. The Production Readiness process is documented in the handbook.
-
infra-mgmt: Infrastructure management repository at https://gitlab.com/gitlab-com/gl-infra/infra-mgmt used to automate the creation and management of GitLab’s repositories on GitLab.com, including enforcement of baseline project requirements, managing Vault integration, secrets rotation, and mirroring between GitLab instances. -
SLA (Service Level Agreement): Defined response times and resolution targets for various operational activities, including security updates, policy compliance, and incident response.
-
CVE (Common Vulnerabilities and Exposures): Publicly disclosed security vulnerabilities tracked at cve.mitre.org that require timely remediation according to defined SLAs based on severity levels.
-
CVSS (Common Vulnerability Scoring System): Industry-standard scoring system (0-10) used to assess the severity of security vulnerabilities. See FIRST CVSS specification for details.
Roles
Three distinct roles drive the component addition process. Each brings specific expertise. Each owns different responsibilities.
| Role | Team | Responsibilities |
|---|---|---|
| Component Owner | Team introducing and owning the new component | The stage group team or infrastructure team introducing the new component. The team owns it from conception through production. Drives the engagement process forward. Creates the artifacts: Container Images, Terraform modules, Helm charts, design documents. |
| Design Reviewer | Production Engineering (Staff+ IC) | Evaluates the design. Asks difficult questions about scale, operations, architecture, and security. Their approval signals that the design can survive production’s demands and would be viable in Self-Managed in future. |
| Integration Engineers | Production Engineering | Guides the component into GitLab.com’s infrastructure. Reviews code against the approved design. Verifies policy compliance. Ensures the implementation matches the promise. |
The Vision: Self-service Infrastructure
The Component Ownership Model pushes infrastructure component ownership left. Teams that propose components own them, from Idea to Production and beyond into ongoing maintenance and support. Component Owners maintain separate repositories for their Infrastructure-as-Code, avoiding adding their changes directly to Infrastructure repositories. By maintaining their own modules, they control their release cycles, and respond to alerts and incidents. Infrastructure teams provide platforms, a paved path, guidance and guardrails. The goal is to avoid roadblocks.
Infra-Mgmt will be used to automate repository management, mirroring, secret management and rotation.
Future iterations may include a self-service platform that automates, GCP sandbox resource provisioning. Teams could spin up standardized environments with Atlantis for Terraform automation and Vault for secrets management. This vision builds on proven patterns while removing infrastructure teams from the critical path.
Maintaining Clear Boundaries
Unlike today, component IaC definitions will not reside in Config-Mgmt or k8s-workloads repositories. They exist in their own repositories under the https://gitlab.com/gitlab-com/gl-infra/components namespace (TBD). Component owners own these repositories, have owner rights and merge their own changes. They manage releases.
Teams build components as Helm charts for Kubernetes workloads, or Terraform Modules for cloud resource provisioning. They define Metrics Catalog entries for observability. Infrastructure platforms consume these modules as isolated, well-defined, versioned dependencies, instead of absorbing weakly-owned changes into a monolithic repository.
For modules, Convention-over-Configuration is strongly favoured,
and using
common-ci-tasks CI Components and
common-template-copier Project Templates
will encourage this approach.
Building on Proven Foundations
The common-ci-tasks repository provides standardized CI components for consistent project builds.
Teams inherit policy enforcement, testing frameworks, and deployment patterns.
This approach will avoid reinventing wheels and divergent practices, encouraging a paved-path approach.
GitLab Infrastructure team already makes use of Copier for project templates stored in the common-template-copier project.
The Copier Templates establish patterns that make components maintainable and consistent, and provide automated upgrades to projects to migrate around breaking changes.
Using these Copier templates for new projects is mandatory.
Policy as Code
For Component Ownership Model, Infrastructure standards live as code, not documentation.
Teams consume versioned policies published as OCI images.
conftest will be used to valid modules against policies defined by Infrastructure policies.
Additionally, unit testing for Helm (using helmunit) and Terraform (using terraform test) will be required.
checkov scans will further enforce broader, industry standard policies.
Policy versions follow semantic versioning:
- Major versions introduce breaking changes requiring major and disruptive code updates
- Minor versions add new rules
- Patch versions fix bugs without breaking existing components
Each project will declaratively define the policy versions supported. This will be verified through CI/CD checks on the project, ensuring that developers are aware of policy breaches as soon as possible. Teams declare their supported policy version. Renovate proposes updates to the policy documents. Infrastructure communicates standards through policy releases, not meetings or checkboxes in a merge request template.
Policy Evolution
Infrastructure evolves policies based on operational experience, the need to nudge teams in a specific direction, or even small linter fixes. New attack vectors may require new security rules. Performance issues drive resource policies. Teams consume these updates at their own pace within support windows, but the Infrastructure Platforms team may require certain minimum versions of the policies to be enforced before allowing the team to integrate a module. Although the Component Owner team will be responsible for upgrading to the new version, these is a well-established approach to automating upgrades all GitLab projects using the copier templates, using Source Migrations.
Continuous Validation
Since policy checks are defined in code, and integrated into the standard CI components used in component projects, policies are validated on each push and failed checks block merges. Teams know immediately when they violate standards.
Policy violations during development are learning opportunities. Teams can temporarily disable specific policies with justification. These exceptions require review during integration.
Observability as Code
Metrics Catalog integration starts during development.
Teams define PodMonitor and ServiceMonitor
configurations as part of helm chart definitions.
Services define their metrics-catalog configurations alongside Helm Charts. These configurations generate dashboards and alerts. Alerts are automatically routed to the owning team.
Decoupled Lifecycles
Component repositories maintain their own release cycles. Teams use semantic commits to drive an automated semantic release process.
Infrastructure repositories reference specific component module versions, but don’t contain component (IaC) code. Teams propose version updates through merge requests, or Renovate will open them automatically. Upgrades need to be validated in staging before production.
By using versioned modules, there is a physical limit to the drift that can occur between the implementations in each environment. This is different from the copy-pasta style approach sometimes used at present, which results in configuration drift between environments over time.
Importantly, by using a single module for multiple environments, teams need to consider the interface to their module and the appropriate level of abstraction. This is an important part of the design process, but can be missed if you’re simply declaring Terraform resources.
Service-Level Agreements
Infrastructure Platforms and Component Owner Teams will both commit to maintaining the following SLAs.
Infrastructure Platforms Team SLAs
As the platform provider, the Infrastructure Platforms department will commit to the following SLAs.
-
Initial Design Review Response: 10 business days to provide initial feedback on design documents
-
Integration Review Turnaround:
- Initial review: 2 business days for first pass
- Subsequent reviews: 1 business day for re-reviews after changes
-
Support Response Times:
- Blocking issues: 2 business days
- Non-blocking questions: 5 business days
-
Platform Availability:
- CI/CD pipeline availability, no upstream blockers: 99.5% uptime
Component Owner Team SLAs
The Component Owner will commit to the following SLAs. - Component Owners undertake to follow the Security Department’s Vulnerability mitigation and remediation SLAS - For embargoed vulnerabilities: Must comply with coordinated disclosure timelines.
-
Tooling and Dependency Updates:
- Breaking tool updates (Terraform, Helm major versions): 30 days from Infrastructure Team adoption
- Security updates for dependencies: Follow security incident SLAs above
- Provider plugin updates: 14 days for critical providers (GCP, Kubernetes)
- Note: Renovate will manage the creation of these MRs, and with sufficient test coverage, these updates should low effort. However, if components require manual testing, this will quickly become a burden on component owners. It is highly recommended that proper automated tests are maintained by component owners to reduce dependency upgrade overhead.
-
Policy Compliance Updates:
- Major policy versions: 90 days from release
- Minor policy versions: 30 days from release
- Security-related policy updates: 14 days
-
Operational Response:
- Production incidents (S1/S2): 15-minute response time
- Performance degradation: 1 hour response time
- Capacity alerts: X business days
-
Documentation Maintenance:
- Runbook updates: Delivered as part of any significant change project
-
On-call Coverage:
- The Component Owner team must provide either a Tier 1 On-Call or Tier 2 On-Call. Note: a new 24x5 Pilot On-Call is being considered at present, and this may be used once it is available.
- Escalation path configured in PagerDuty, through automation
- Handoff procedures documented.
Measurement and Reporting
- As much as is reasonably possible, the GitLab Product should be used to manage GitLab security finding reporting.
- Quarterly reviews between Infrastructure Platforms and Component Owners
- Annual SLA review and adjustment based on operational data
SLA Exceptions and Escalations
- Grace periods may be extended with Infrastructure Platform Leadership approval
- Waivers require director-level approval from both teams
- Non-compliance triggers escalation to director-level heads after:
- 2 missed SLAs in a quarter
- Any critical security SLA breach
- Repeated violations of the same SLA
- Reported in SaaS Availability Weekly Standup
Making it real
The Component Ownership Model succeeds through automation and clear ownership. Teams move faster because standards are automated.
Component owners must embrace operational ownership. Infrastructure teams must provide platforms, not permission.
COM Lifecycle Stages
Stage 1: Design Stage
The process begins with engagement and a design. The Component owner produces a small design document. This is not a sprawling specification but a focused proposal, specifically covering the deployment of the component to GitLab.com. This same documentation will later be used as part of the service runbooks, and production readiness process.
A Staff+ engineer in the Production Engineering sub-department will work with the Component Owner to validate the design.
A set of prerequisites questions will need to be covered before approval can be given, such as:
Production Readiness Design Review Checklist
Note: this section may evolve into a section in the broader Production Readiness checklist.
-
Portability Although this process focuses on GitLab.com, components must should be forward compatible with GitLab’s other deployment models. A feature requiring proprietary cloud services without self-managed equivalents will not pass review.
-
Multi-tenancy, Single-tenancy and Isolation Does this component design consider future deployments into other GitLab platforms, such as Cells and Dedicated? Is it forward-compatible with these environments?
-
Observability Standards Does the component emit structured logs and metrics compatible with GitLab’s observability stack?
-
Dependency Management “Are all external dependencies documented with version constraints, and can they operate in restricted network environments?”
-
Data Lifecycle Is there a clear data retention and deletion strategy that supports compliance requirements?
-
Performance Degradation Does the component gracefully degrade under load, for example, with clear circuit breakers and backpressure mechanisms?
-
Configuration Management Can all configuration be managed through GitLab’s standard configuration systems (Terraform, Kubernetes) without manual clickops operations or hardcoded values?
-
Cross-region Considerations Will the component be forward-compatible with geo-distributed deployments in future?
-
Resource Quotas Does the component implement resource quotas and rate limiting that can be configured per-tenant or per-deployment?
-
Upgrade Path Is there a zero-downtime upgrade path that supports rolling updates?
-
Security Boundaries Are security boundaries clearly defined with appropriate authentication and authorization checkpoints?
-
Disaster Recovery Does the component support backup/restore operations that align with the RPO/RTO requirements for GitLab.com. Is the component forward compatible with the various RPO/PTO requirements across Cells and Dedicated?
-
Integration Testing Can the component be fully tested in isolation and as part of integrated test suites without external dependencies?
-
Data Residency and Privacy Controls Is the component forward compatible with the data residency requirements and privacy controls of Dedicated and Dedicated-for-Government deployments?
-
Extensibility Without Core Modifications Does the interface for the component allow the component’s behavior be extended through configuration without modifying core code, supporting different deployment configurations?
-
Component Replaceability and Independence Is the module designed with clear interface boundaries and loose coupling to enable independent replacement or migration without affecting other services?
Stage 2: Development Stage
Development follows design approval. This stage is driven by the Component Owner team. Component Owners build in their repositories and own the pace of development. Changes can be merged in the component repository without Infrastructure Platforms involvement. Within policy constraints, development can occur according to preferred approach of the Component Owner team. This will reduce the need to wait for Infrastructure Platform reviews during development.
Stage 3: Integration Stage
Once the component is ready, the Component Owner team and the Integration SRE collaborate on delivering the change, first to staging and then production.
As a first step, an MR is opened in the appropriate Infrastructure Platforms repository, such as Config-Mgmt or k8s-workloads. The review should be assigned to the Integration SRE.
Changes to integrate the module into each successive environment should be carried out in separate MRs, so that each change is tested in staging before being rolled out in canary and finally production.
Once the change is ready, the Integration SRE will review the change. This will include a review of the Component module, to ensure that:
- The implementation matches the agreed design (within reason).
- Policy versions are up-to-date, and
common-ci-tasksbuild components are up-to-date. - Test coverage and quality
- Operational readiness (monitoring, alerting, runbooks)
- Security posture
- Resource efficiency
- Backup and recovery procedures
The reviewing Integration SRE should, whenever possible, avoid being a “human linter”. Focusing on small menial linter-style issues should be avoided. Computers can lint for us, and human time is far more valuable for focusing on the big picture. Sometimes by focusing on small niggles, the reviewer may fail to see the wood for the trees.
Note: this isn’t to say that linting isn’t important. SREs should look to
automate linter issues in common-ci-tasks.
This is better since it reduces gatekeeping, allows Component Owner Teams to learn about
these issues earlier in the development cycle, and prevents unexpected delays
later in the process.
During the integration stage, multiple iterations of review and deployment may take place, until the component is deemed to be sufficiently stable and ready for deployment to production.
Each of these changes will be released as a new semver release of the module.
Stage 4: Operations and Maintenance
Once the component has graduated to production, ongoing feature improvements can iteratively be added, along with other changes, such as dependency upgrades, performance improvements and technical debt resolution.
Ongoing review of operational metrics is expected, which include storage growth, operating cost, and any other metrics relevant to the new component.
The responsibility for these tasks will fall on the team owning the component.
From Idea to Production, a runbook for Component Owner teams
Stage 1: Design Stage
- Follow the Production Readiness Process to open a Production Readiness issue. The earlier this is done, the better. Opening the Production Readiness issue kicks initiates the process and starts the process of allocating a Design Reviewer “slot”.
- Create a Production Readiness MR, as per the Production Readiness Process. At this stage, the document will be fairly empty, but the Component Design can be carried out in this draft document.
- A component may have either a Terraform Module, a Helm Module or both.
- Define the interface for the component and document it in the production readiness draft MR. The interface is, in Terraform, the inputs, or in Helm, the values.
- Produce a diagram and description of the cloud resources that the module will consume.
Stage 2: Development Stage
- Declare the project in https://gitlab.com/gitlab-com/gl-infra/infra-mgmt, to create it in https://gitlab.com/gitlab-com/gl-infra/components.
- Although Infra-Mgmt is not currently optimized for self-service updates, it is possible for any engineer within the company to manage their projects through the system.
- Work to improve the UX of Infra-Mgmt, making it better for self-service is being tracked in https://gitlab.com/groups/gitlab-com/gl-infra/-/epics/1632.
- Clone the new empty project, and follow the instructions in https://gitlab.com/gitlab-com/gl-infra/common-template-copier to apply the base template for the project. Push the initial commit to GitLab.
- Start iterating on development of the module. MR reviews can be conducted within the team.
- Build unit tests for your infrastructure using the scaffolding provided by the Copier template.
- Integration test the changes using Sandbox accounts, KinD and other development tooling.
- Monitor any policy failures, and address these early.
- Use Semantic Commits to control versioning. Semantic Versioning will automatically tag and release new versions of your module automatically, and publish these versions.
Stage 3: Integration Stage
- When the team is confident that the component is ready for staging, the Component Owner team should open an MR in Config-Mgmt or k8s-workloads repositories.
- The change should target to Staging environment and should reference a specific version of the component module.
- The Component Owner team will not have merge access to the Infrastructure Platforms projects, but should assign to the Integration SRE for review.
- The Integration SRE will conduct a review of the MR and also ensure that the upstream module meets the proposed design.
- If any changes need to be done upstream, these should be carried out in the upstream module with Semantic Releases used to publish new versions of the module, until the review is completed and the change is merged to the Staging environment.
- The Component Owner team then validates the change, ensuring that it is working as expected in the staging environment.
- Component Owner team verifies observability, alerts, etc.
- Some additional work will need to be done by the Observability Team to allow teams to declare and test their observability directly in their own modules, without needing to define these configurations in Infrastructure repositories (such as Infrastructure Runbooks).
- This work will likely be done as part of the https://gitlab.com/groups/gitlab-com/gl-infra/-/epics/1637 epic.
- Through multiple iterations to the upstream module, and to the integration project, the change will be rolled into production.
- The Production deployment will need to be aligned with the wider Production Readiness process, with the production deployments being dependent on the production readiness review status. However, since the project is using Infrastructure templates, Infrastructure Policies and Infrastructure best-practices, the production readiness review is likely to to be significantly faster than one in which components are produced without following the paved path.
Stage 4: Maintenance
- Once the change is deployed, further progressive iterative changes can be made by the team in the upstream modules.
- As during the development phase, changes are owned by the Component Owner team.
- Integration can usually be done by a version bump to the downstream Infrastructure Platforms project.
- Version bumps MRs will be created automatically by Renovate, but will require a review by an Infrastructure Platform engineer for MR approval. In most cases, for small changes, these will be quick reviews.
- Renovate will also propose dependency upgrades to the component module itself. Some of these will address CVEs in downstream dependencies and the team will be responsible for addressing these (possibly within an SLA).
- Some shared components, such as Terraform and Helm will need to closely track the versions used on GitLab.com in the Config-Mgmt and k8s-workloads repositories. The team will be responsible for performing these upgrades, although Renovate will open the MRs.
- The team will be responsible for Capacity Planning issues related to the component.
- Similar to how Observability for components will be defined by Component Owners in-module, the same approach will be used to define saturation points for Capacity Planning.
- This work will likely be done as part of the https://gitlab.com/groups/gitlab-com/gl-infra/-/epics/1637 epic.
- The team will need to maintain their on-call schedule for escalations to the service.
- Incident.io resources should be managed alongside Infra-Mgmt component modules.
Next steps
Deploying your component to GitLab.com is only the first step in a much larger process of bringing a new component to all GitLab customers.
Next, we’ll need to consider Cells, GitLab Dedicated, Dedicated for Government, Self-Managed using GET, Omnibus and Cloud Native GitLab.
Some of these processes for handling new components are undergoing change, and those changes are still underway. Once they are complete, this guide will reference the appropriate next steps.
Appendix: Case Study: GitLab’s Tenant Observability Stack (TOS)
The Challenge
GitLab operates multiple deployment models: the multi-tenant GitLab.com, single-tenant GitLab Dedicated, GitLab Cells, and Dedicated for Government. Each has unique requirements for scale, isolation, and compliance, yet all need comprehensive observability. Without a unified approach, each platform team would implement their own observability solutions, leading to duplicated effort, inconsistent tooling, and operational toil.
The Solution: Component Ownership in Action
The Observability Team created the Tenant Observability Stack (TOS) as a reusable Terraform module. Instead of embedding observability directly into each platform, TOS provides a complete observability solution that adapts to different deployment scenarios through configuration.
Clear Ownership Boundaries
The Observability Team owns the TOS module completely. They:
- Maintain the module in
gitlab.com/gitlab-com/gl-infra/terraform-modules/observability/tenant-observability-stack - Release updates through semantic versioning
- Provide comprehensive documentation
- Handle security updates, dependency upgrades and add features to the module
- Treat module consumers as their customer
- Treat TOS as an internal product
Platform teams (Dedicated, Cells, Production Engineering) consume TOS as a versioned dependency. They:
- Configure TOS for their specific requirements
- Control when to adopt new versions, progressively staggering roll-outs through staging to production environments.
- Focus on their platform-specific challenges
Measurable Benefits
Consistency: All platforms use the same dashboards, alerts, and tools, reducing cognitive load and enabling engineer mobility.
Independent development: The Observability Team iterates rapidly without disrupting platform deployments. Features roll out through simple version updates.
Cost efficiency: Consolidating observability development eliminates duplication. Improvements benefit all deployments simultaneously.
Key Lessons
-
Define clear interfaces: Stable module inputs and outputs enable platform teams to integrate confidently
-
Invest in automation: Automated testing, versioning, and deployment reduce manual intervention
-
Enable self-service: Comprehensive documentation allows platform teams to adopt and configure independently
-
Maintain backward compatibility: Semantic versioning with migration guides ensures smooth upgrades
-
Iterate based on feedback: Regular engagement with platform teams drives practical improvements
The Impact
TOS demonstrates that the Component Ownership Model transforms infrastructure management.
By packaging observability as a module with clear ownership, we achieved:
- Consistent observability across diverse platforms
- Rapid feature delivery without platform disruption
- Reduced operational burden on platform teams
- Scalable foundation for future growth
The success of TOS proves that well-defined component ownership, combined with thoughtful interfaces and automation, creates infrastructure components that serve as multipliers – enabling teams to focus on their unique value while leveraging best-in-class shared capabilities.
For more details, see the TOS module documentation and the Cells Observability architecture.
0712f8f3)
