Data Insights Platform Hierarchical Data Retrieval Optimization
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| accepted |
ahegyi
|
ankitbhatnagar
|
dennis
|
group platform insights | 2025-02-27 |
Summary
With the Data Insights Platform (DIP), we can optimize existing GitLab features and improve scalability by leveraging alternative database systems for data querying. The platform will also provide real-time analytical capabilities through ClickHouse, which is well-suited for processing large volumes of data.
Proposal
Leverage the Data Insights Platform, utilizing Siphon for efficient data synchronization with ClickHouse. The ingested data in ClickHouse will be enhanced through the use of materialized views, specifically designed to support hierarchical queries over large datasets.
Problem statement
Querying data in the group hierarchy involves the following steps when the PostgreSQL database is used:
- Locate the group and its subgroups (unbounded, there is no application limit on the number of allowed subgroups).
- For each item, look up the associated resource (for example issues).
- Apply additional filters and joins.
- Count or sort the records.
- Present the results to the user.
A simplified database query:
SELECT
issues.*
FROM issues
WHERE
-- this subquery may contain several thousands of projects
project_id IN (SELECT id from projects WHERE ...)
ORDER BY created_at, id
LIMIT 21
An example database query from the codebase:
SELECT
"issues".*
FROM
"issues"
INNER JOIN "projects" ON "projects"."id" = "issues"."project_id"
LEFT JOIN project_features ON projects.id = project_features.project_id
WHERE (NOT EXISTS (
SELECT
1
FROM
"banned_users"
WHERE (issues.author_id = banned_users.user_id)))
AND "projects"."namespace_id" IN (SELECT namespaces.id FROM (
SELECT
namespaces.traversal_ids[array_length(namespaces.traversal_ids, 1)] AS id FROM "namespaces"
WHERE
"namespaces"."type" = 'Group'
AND (traversal_ids @> ('{9970}'))) namespaces)
AND (EXISTS (
SELECT
1
FROM
"project_authorizations"
WHERE
"project_authorizations"."user_id" = 4156052
AND (project_authorizations.project_id = projects.id)
AND (project_authorizations.access_level >= 10))
OR projects.visibility_level IN (10, 20))
AND ("project_features"."issues_access_level" IS NULL
OR "project_features"."issues_access_level" IN (20, 30)
OR ("project_features"."issues_access_level" = 10
AND EXISTS (
SELECT
1
FROM
"project_authorizations"
WHERE
"project_authorizations"."user_id" = 4156052
AND (project_authorizations.project_id = project_features.project_id)
AND (project_authorizations.access_level >= 10))))
AND "issues"."state_id" = 1
AND ("issues"."project_id" IS NULL
OR "projects"."archived" = FALSE)
AND "issues"."work_item_type_id" IN (1, 2, 5, 7, 6, 3)
ORDER BY
"issues"."created_at" DESC, "issues"."id" DESC
LIMIT 21
Such queries can easily take 3–10 seconds to run on the current production database. A similar query that counts the total number of issues for the gitlab-org group currently times out. Although these queries are fairly well supported by database indexes, the primary issue lies in the large volume of data that PostgreSQL needs to scan—something that can’t be further optimized.
Optimizations have been attempted in the past to improve the performance of such queries, but essentially, these optimizations won’t solve all the scaling issues associated with the hierarchical database queries:
- Addition of
namespaces.traversal_idsto our namespaces table as an optimization for fast hierarchy lookup. IN-operator optimization- Hierarcy caching
The problem gets more complicated if we start extending our features to support organizational level lookups. Organizations can contain several group hierarchies which multiplies the data the database will need to scan.
Fundamentally, we have reached the limit of how far we can optimize hierarchical queries. This is making, and will continue to make, delivering results for some of our largest customers very difficult. Engineers see this today when developing features and it becomes very difficult to write performant queries for very large group/project hierarchies.
Overview of the optimization in DIP
Within the Data Insights Platform, optimizing this query would involve a few key steps. These steps are fairly general, so the same approach could be applied to other group-level features like merge requests or epics.
Data synchronization
Siphon (blueprint) enables low-latency replication of PostgreSQL tables to other database systems, typically with just 1–5 seconds of data lag. This is low enough to treat the data as consistent and usable for “real-time” queries.
The replicated tables maintain the same structure as they have in PostgreSQL, making integration straightforward.
project_authorizations table in PostgreSQL:
CREATE TABLE project_authorizations (
user_id bigint NOT NULL,
project_id bigint NOT NULL,
access_level integer NOT NULL,
);
ALTER TABLE ONLY project_authorizations
ADD CONSTRAINT project_authorizations_pkey PRIMARY KEY (user_id, project_id, access_level);
siphon_project_authorizations table in ClickHouse:
CREATE TABLE gitlab_clickhouse_development.siphon_project_authorizations (
`user_id` Int64,
`project_id` Int64,
`access_level` Int64,
`_siphon_replicated_at` DateTime64(6, 'UTC') DEFAULT now(),
`_siphon_deleted` Bool DEFAULT false
)
-- define the version and delete columns
ENGINE = ReplacingMergeTree(_siphon_replicated_at, _siphon_deleted)
PRIMARY KEY (user_id, project_id)
ORDER BY (user_id, project_id)
Database table engine for Siphon
Siphon tables in ClickHouse (by convention, table names start with the siphon_ prefix) use a specialized table engine called ReplacingMergeTree, which is optimized for handling data changes.
ClickHouse doesn’t support efficient single-row updates or deletes — there’s no UPDATE statement in the traditional sense. Instead, changes are handled through inserts, and the engine deduplicates data in the background based on the primary key(s).
Deduplication is controlled by two special columns managed by Siphon:
_siphon_replicated_at: the version of the row, usually a timestamp_siphon_deleted: a flag indicating whether the row has been deleted
An “update” is just an INSERT with a newer version value:
INSERT INTO siphon_project_authorizations
(user_id, project_id, access_level, _siphon_replicated_at, _siphon_deleted)
VALUES (1, 1, 10, '2025-04-06 18:12:52.234564', false);
A “delete” is also an INSERT, but with _siphon_deleted = true and a newer version value:
INSERT INTO siphon_project_authorizations
(user_id, project_id, access_level, _siphon_replicated_at, _siphon_deleted)
VALUES (2, 1, 10, '2024-04-06 13:43:05.786542', true);
At any given time, multiple rows with the same primary key might exist.
Example table data:
user_id |
project_id |
access_level |
_siphon_replicated_at |
_siphon_deleted |
|---|---|---|---|---|
| 1 | 1 | 30 | 2025-04-05 03:10:43.118265 | false |
| 2 | 1 | 10 | 2024-01-03 02:32:37.703416 | false |
| 1 | 2 | 10 | 2025-03-14 09:07:22.847632 | false |
| 1 | 1 | 10 | 2025-04-06 18:12:52.234564 | false |
| 2 | 1 | 10 | 2024-04-06 13:43:05.786542 | true |
Although the table contains five rows, deduplication should result in just one row. Deduplication is automatic, asynchronous and handled by ClickHouse:
SELECT * FROM siphon_project_authorizations FINAL
user_id |
project_id |
access_level |
_siphon_replicated_at |
_siphon_deleted |
|---|---|---|---|---|
| 1 | 1 | 10 | 2025-04-06 18:12:52.234564 | false |
Note: FINAL is not recommended for production use as it might collapse/merge rows in query time.
How did we get here?
Let’s look at the primary key pairs:
(1, 1): The first row is overridden by the fourth row, which has a newer version and lower access level.(2, 1): The second row is overridden by the fifth row, which marks it as deleted.
You can simulate the effect of deduplication at query time with the following:
SELECT * FROM (
SELECT
user_id,
project_id,
argMax(access_level, _siphon_replicated_at) AS access_level,
argMax(_siphon_deleted, _siphon_replicated_at) AS deleted
FROM siphon_project_authorizations
GROUP BY user_id, project_id
) pa
WHERE deleted = false
Note: This deduplication pattern is essential when working with ReplacingMergeTree tables to avoid returning two records with the same primary key.
Query performance for Siphon tables
Siphon database tables are optimized for accessing data via the defined primary key(s). The primary key definition for the tables are always exactly the same as the PostgreSQL counterpart.
This means that queries targeting other columns will not perform well. This is an example for filtering issues for a project in ClickHouse:
SELECT *
FROM siphon_issues
WHERE
project_id = 278964
ORDER BY created_at, id
LIMIT 20;
Note: for simplification, the deduplication part is not added to the example queries.
Performance is very slow, the query scans the whole table.
20 rows in set. Elapsed: 40.830 sec. Processed 100+ million rows.
The group-level query would likely perform worse, as we would need to query all projects or namespaces for the group hierarchy from the siphon_namespaces table.
Optimizing queries for a different access pattern other than the primary key in ClickHouse is not as easy as simply adding a database index. Database indexes are effective if the primary key is also filtered so the data to be scanned is already reduced.
Materialized Views on top of Siphon tables
Materialized views in ClickHouse let us define efficient access patterns for our database tables. Think of them as INSERT triggers; whenever data is inserted into the source table, the materialized view automatically gets updated too.
This works well for us because both UPDATE and DELETE operations in ClickHouse are represented as INSERTs. As long as the primary key doesn’t change (see the caveats section), the materialized view will stay in sync with the source table.
Here’s an example of a materialized view that makes it faster to query by project_id:
CREATE TABLE issues_by_project
(
-- list the same columns as in siphon_issues
)
ENGINE = ReplacingMergeTree(_siphon_replicated_at, _siphon_deleted)
PRIMARY KEY (project_id, id)
ORDER BY (project_id, id);
CREATE MATERIALIZED VIEW issues_by_project_mv TO issues_by_project
AS SELECT *
FROM siphon_issues;
Running queries against this new materialized view performs much better:
SELECT *
FROM issues_by_project
WHERE
project_id = 278964
ORDER BY created_at, id
LIMIT 20;
20 rows in set. Elapsed: 0.024 sec. Processed 125.83 thousand rows
As you can see, materialized views help optimize queries with specific filters. Even though ClickHouse processed over 125,000 rows, that’s still considered efficient — unlike in PostgreSQL, scanning 1–5 million rows per query is pretty normal in ClickHouse due to its low I/O cost.
Adding more filters to the query won’t affect the performance significantly, as long as those filters are targeting other columns in the table. For example, adding a filter on author_id would perform just as well as the query above.
You can also improve performance further with optimizations like data skipping indexes, if needed.
Materialized view for hierarchical lookups
The previous example was addressing project_id based lookups which can be optimized quite well in PostgreSQL with a database index. Going back to the original problem; How can we optimize data access queries in the group hierarchy?
The key element for the optimization is the traversal_ids array from the namespaces table which contains all ancestors for a given namespace record.
A namespace record can be:
- Top-level group
- Subgroup
- Project (called:
ProjectNamespace) - Personal namespace (called
UserNamespace)
This is the traversal ids value of the Siphon project on GitLab.com: [9970,55154808,95754906]
9970:gitlab-orgtop-level group.55154808:analytics-sectionsub-group.95754906:siphonproject namespace.
The project namespace has a 1:1 mapping with the projects table. In this case it points to a project row with id=63106760.
Organization, group, subgroup and project level queries can be optimized by making a materialized view where all issues are stored with the respective traversal_ids value.
Formatting of the traversal_ids
ClickHouse is not very efficient when filtering dynamic array prefixes. Turning traversal_ids into a string yields much better performance. We can also add the organization into the mix, by simply prepending the organization id.
The traversal_ids becomes traversal_path: 1/9970/55154808/95754906/ (1 is the organization id)
Building on top of the siphon_namespaces table, we can create a materialized view to create the formatted traversal_path:
CREATE TABLE namespace_traversal_paths(
`id` Int64 DEFAULT 0,
`traversal_path` String DEFAULT '0/',
`version` DateTime64(6, 'UTC') DEFAULT now(),
`deleted` Bool DEFAULT false
)
ENGINE = ReplacingMergeTree(version, deleted)
PRIMARY KEY id
ORDER BY id
SETTINGS index_granularity = 512; -- optimize single-row value lookups
CREATE MATERIALIZED VIEW namespace_traversal_paths_mv TO namespace_traversal_paths
(
`id` Int64,
`traversal_path` String,
`version` DateTime64(6, 'UTC'),
`deleted` Bool
)
AS SELECT
id,
-- concat organization_id and the traversal_ids array
if(length(traversal_ids) = 0, concat(toString(ifNull(organization_id, 0)), '/'), concat(toString(ifNull(organization_id, 0)), '/', arrayStringConcat(traversal_ids, '/'), '/')) AS traversal_path,
_siphon_replicated_at AS version,
_siphon_deleted AS deleted
FROM gitlab_clickhouse_development.siphon_namespaces
With this materialized view we can easily query the traversal_path value for a given namespace id:
SELECT traversal_path
FROM namespace_traversal_paths
WHERE
id = 95754906
LIMIT 1;
-- 1/9970/55154808/95754906/
Creating the issues materialized view
Creating the materialzied view involves a JOIN where we connect the issues records via the namespace_id column with the namespace_traversal_paths table.
The materialized view will contain all columns from the siphon_issues table plus one extra column called traversal_path from the JOIN above. Optionally, columns which doesn’t need to be filtered at all can be skipped to save disk space.
CREATE TABLE IF NOT EXISTS hierarchy_issues
(
traversal_path String,
id Int64,
title Nullable(String),
author_id Nullable(Int64),
project_id Nullable(Int64),
created_at Nullable(DateTime64(6, 'UTC')),
updated_at Nullable(DateTime64(6, 'UTC')),
milestone_id Nullable(Int64),
iid Nullable(Int64),
updated_by_id Nullable(Int64),
weight Nullable(Int64),
confidential Bool DEFAULT false,
due_date Nullable(Date32),
moved_to_id Nullable(Int64),
time_estimate Nullable(Int64) DEFAULT 0,
relative_position Nullable(Int64),
service_desk_reply_to Nullable(String),
last_edited_at Nullable(DateTime64(6, 'UTC')),
last_edited_by_id Nullable(Int64),
closed_at Nullable(DateTime64(6, 'UTC')),
closed_by_id Nullable(Int64),
state_id Int8 DEFAULT 1,
duplicated_to_id Nullable(Int64),
promoted_to_epic_id Nullable(Int64),
health_status Nullable(Int8),
sprint_id Nullable(Int64),
blocking_issues_count Int64 DEFAULT 0,
upvotes_count Int64 DEFAULT 0,
work_item_type_id Nullable(Int64),
namespace_id Nullable(Int64),
start_date Nullable(Date32),
version DateTime64(6, 'UTC') DEFAULT now(),
deleted Bool DEFAULT FALSE
)
ENGINE = ReplacingMergeTree(version, deleted)
PRIMARY KEY (traversal_path, id);
CREATE MATERIALIZED VIEW hierarchy_issues_mv TO hierarchy_issues
AS WITH
cte AS
(
SELECT *
FROM siphon_issues
),
namespace_paths AS
(
-- look up `traversal_path` values
SELECT
id,
traversal_path
FROM namespace_traversal_paths
WHERE id IN (
SELECT DISTINCT namespace_id
FROM cte
)
)
SELECT
-- handle the case where namespace_id is null
multiIf(cte.namespace_id != 0, namespace_paths.traversal_path, '0/') AS namespace_path,
cte.id Int64,
cte.title,
cte.author_id,
cte.project_id,
cte.created_at,
cte.updated_at,
cte.milestone_id,
cte.iid,
cte.updated_by_id,
cte.weight,
cte.confidential,
cte.due_date,
cte.moved_to_id,
cte.time_estimate,
cte.relative_position,
cte.service_desk_reply_to,
cte.last_edited_at,
cte.last_edited_by_id,
cte.closed_at,
cte.closed_by_id,
cte.state_id,
cte.duplicated_to_id,
cte.promoted_to_epic_id,
cte.health_status,
cte.sprint_id,
cte.blocking_issues_count,
cte.upvotes_count,
cte.work_item_type_id,
cte.namespace_id,
cte.start_date,
cte._siphon_replicated_at AS version,
cte._siphon_deleted AS deleted
FROM cte
LEFT JOIN namespace_paths ON namespace_paths.id = cte.namespace_id
Evaluating the performance of the materialized view
With the traversal_path column present in the table, we can now run group-level queries efficiently:
SELECT *
FROM hierarchy_issues
WHERE
startsWith(traversal_path, '1/9970/')
ORDER BY created_at, id
LIMIT 20;
20 rows in set. Elapsed: 0.047 sec. Processed 780.83 thousand rows
The query took 47 milliseconds and it scanned only 780000 rows.
Let’s look out a COUNT query with state distribution:
SELECT state_id, COUNT(*)
FROM hierarchy_issues
WHERE
startsWith(traversal_path, '1/9970/')
GROUP BY state_id
2 rows in set. Elapsed: 0.007 sec. Processed 780.83 thousand rows
We can filter issues down to a particular user by filtering the author_id column:
SELECT *
FROM hierarchy_issues
WHERE
startsWith(traversal_path, '1/9970/') AND
author_id = 4156052
ORDER BY created_at, id
LIMIT 20;
20 rows in set. Elapsed: 0.034 sec. Processed 780.83 thousand rows
Here an optimization could be done via data skipping indexes:
ALTER TABLE hierarchy_issues ADD INDEX idx_author_id author_id TYPE set(1000) GRANULARITY 1;
This helps ClickHouse reduce the number of processed rows:
20 rows in set. Elapsed: 0.022 sec. Processed 421.14 thousand rows
More complex cases
Querying issues often involves several tables and JOINs. With the optimized materialized view, we’ve significantly reduced the amount of records the database needs to scan. Adding extra filters as JOIN need to be carefully considered.
Let’s assume that we also want to filter out issues which is not visible to the current user. This can be done by replicating the project_authorizations table to ClickHouse. The modified query looks like this:
SELECT *
FROM hierarchy_issues
WHERE
startsWith(traversal_path, '1/9970/') AND
project_id IN (
SELECT project_id FROM siphon_project_authorizations WHERE user_id = 4156052
)
ORDER BY created_at, id
LIMIT 20;
20 rows in set. Elapsed: 0.050 sec. Processed 895.52 thousand rows
Note: A similar filter can be added for the banned users. Alternatively, a ClickHouse dictionary could be built for improving the filtering speed.
Direct associations on issues with filters needs to be carefully planned. JOIN statements on the primary key is not as efficient in ClickHouse as in PostgreSQL so queries filtering issue assignees, reviewers or labels will likely need a different solution.
One idea is moving these tables into hierarchy_issues where the has-many association becomes an array:
- label links becomes
label_ids[]. - assignees becomes
assignee_ids[]. - reviewers becomes
reviewer_ids[].
This means that when one of these associations change, the data in the hierarchy_issues table may go out of date. Possible mitigations:
- If the association on the Rails side calls
touchon the associated issue (bumping theupdated_attimestamp) then Siphon will re-insert theissuesrow automatically. This means that associations defined in the materialized view will be also automatically reloaded. - Periodical eventually consistency lookup checks will correct the underlying data. See the caveats section.
Implementation
The Data Insights Platform would ensure that the necessary data is available and up to date in ClickHouse (using Siphon). In case more data is needed on ClickHouse, Siphon would also replicate those tables.
- Check the current ClickHouse database and Siphon configuration to determine which tables are already replicated.
- If the table is missing, create the database table in ClickHouse and configure the replication with Siphon.
- Design a materialized view where the primary key is the
traversal_path+ the primary key of the source table. - Implement the query mechanism by choosing one of the options below.
Initially, there will be two options for querying the data:
- Proto API between DIP and the Rails application.
- In this case the DIP query API would expose a simple interface, data deduplication and other complexities are hidden.
- Use ClickHouse directly from the Rails application (this approach will be deprecated at some point).
- The ClickHouse query is implemented in the Rails application by the feature owner.
Additional maintenance tasks:
Siphon would eventually support database schema changes. This means the schema changes between the PostgreSQL tables and Siphon tables will be automatically handled by the platform.
Earlier in the document, it was mentioned that some inconsistencies might happen as the data changes in the materialized view. The DIP platform would ensure that the configured materialized views regularly checked for inconsistencies and data is corrected as quickly as possible.
Conclusion
ClickHouse offers significantly faster query execution times on large volumes of data compared to PostgreSQL. However, the database schema must be carefully designed to align with the application’s data access patterns. By leveraging materialized views optimized for hierarchical lookups (such as organization, group, and project levels) we can enable real-time analytical capabilities. This approach is generic enough to be easily extended to other core domain objects, such as:
- Merge requests
- Epics
- Vulnerabilities
- Other features which are available on the project or group level.
Overview of the components within DIP:
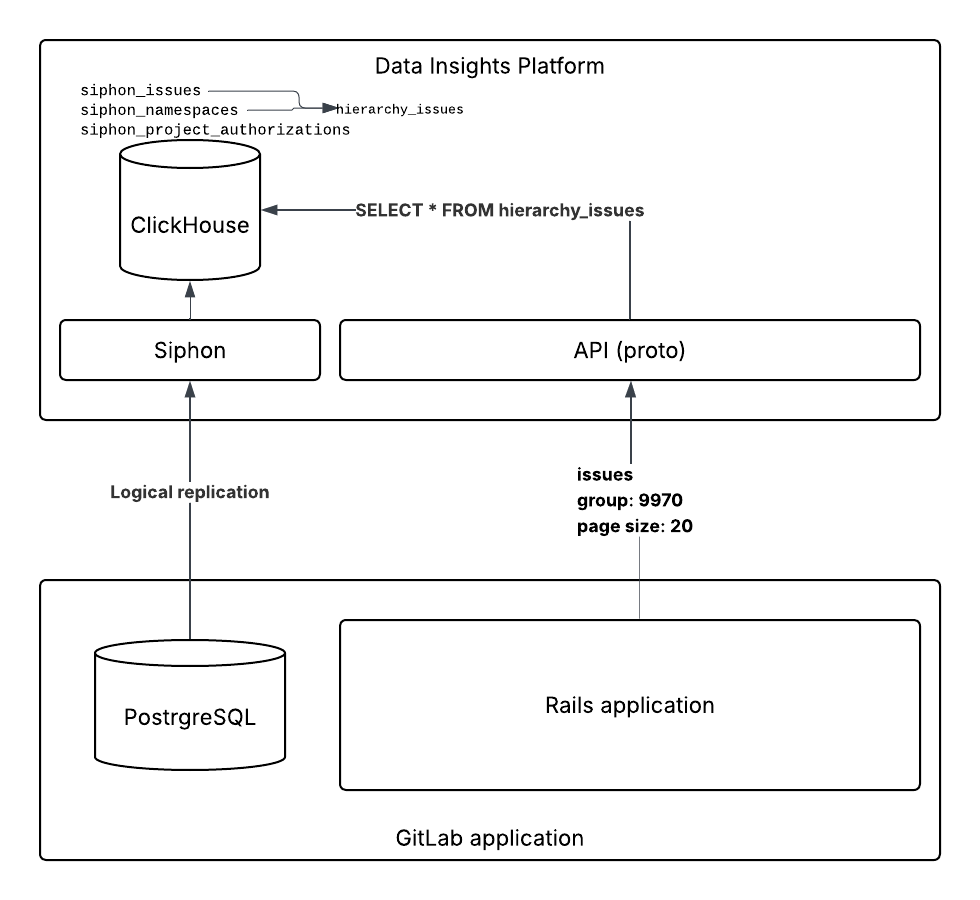
Caveats and Limitations
This proposal presents a relatively complex solution to a scalability problem for which there is currently no other viable alternative.
ClickHouse Query Complexity
Because of the ReplacingMergeTree engine, every query on Siphon tables or materialized views based on them must ensure query-time deduplication. This typically requires additional GROUP BY subqueries, which can make queries harder to generate and more difficult to debug.
Increased Development Costs
The proposal introduces a different database system: ClickHouse. To maintain backward compatibility, queries and filters would need to be maintained with double effort: once for PostgreSQL (existing) and once for ClickHouse (new).
Note: aligning with the proposal in the advanced finders document would somewhat mitigate the costs.
More Moving Parts
The Data Insights Platform introduces more infrastructure components, which also means more potential points of failure:
- Siphon: Handles data synchronization
- ClickHouse: Serves as the analytical data store
- DIP Query API: Acts as the query layer
Data Lag
As with any replication-based system, some level of data lag is inevitable and should be expected. Whilst we can reasonably describe this system as “real-time”, it shouldn’t be used for time-sensitive operations.
Data Inconsistency
As noted in the materialized views section, most data changes are correctly reflected in the corresponding materialized view tables.
However, there’s one edge case where inconsistency can occur. In the hierarchy_issue materialized view, if the traversal_id column changes, for example when a subgroup or project is moved in the hierarchy, the value will not be automatically updated for existing records.
There is a technique to detect and fix this issue, described in this Siphon issue. Using a periodic background worker, the data lag caused by such hierarchy changes can be significantly reduced.
More information about this problem can be found in this blog post.
757fb31f)
