Real Time Analytics with Siphon and Data Insights Platform
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| proposed |
arun.sori
|
ahegyi
|
nicholasklick
|
group platform insights | 2025-07-22 |
Summary
Within ~group::platform insights we have been building foundational blocks like Siphon that aims to unlock real-time analytics on data generated across GitLab in a consistent and performant manner.
This proposal aims to outline design and recommended patterns for implementation that can come together using the foundational pieces to solve our analytical use cases at scale. It does so using an existing use case on Gitlab.com to serve as an example and dig into future possibilities.
Several of the blocks like Siphon or Data Insights Platform (DIP) have their own blueprints regarding particular details on their design which should be referenced separately.
Motivation
The motivation behind building the foundational blocks stem from our work within the Product Usage Data Unification Effort wherein we established a need for unification of all our current multiple ways of collecting, synchronizing and querying analytical data generated across GitLab into a cohesive abstraction.
While we have successfully built individual components like Siphon for real-time data replication, teams across GitLab currently lack clear patterns and examples for combining these pieces into production-ready analytical solutions.
This blueprint addresses the gap between having foundational components and enabling teams to build real-time analytical features efficiently.
An established set of recommended architectural patterns and demonstrating them through a concrete implementation should accelerate the adoption of our unified data platform and provide teams with proven blueprints for building scalable analytical workloads.
Goals
- Define architectural patterns for real-time analytics using Siphon, DIP and ClickHouse
- Establish reusable components and best practices for teams building analytical features
- Demonstrate the pattern through a concrete implementation (internal-first analytics use case)
- Create a foundation for migrating existing analytical workloads to the unified platform
Non-Goals
- Detailed implementation specifications for individual components (covered in separate blueprints)
- Migration strategies for existing production analytical workloads
- Data governance and privacy compliance frameworks (separate initiative)
Proposal
This blueprint proposes standardized architectural patterns for building real-time analytics features at scale using our foundational data platform components: Siphon, NATS, ClickHouse, and Data Insights Platform (DIP). Rather than each team solving data replication and analytics independently, we establish the following proven patterns that can be replicated across GitLab.
- Data Ingestion with Siphon
- Analytics-Optimized Storage with Materialized Views
- Data Consistency with Refresh Mechanisms in Siphon
- Data consistency for tables optimized for access
- Query Interface options
Reference Use Case: Issue and Value Stream Analytics
We will demonstrate these patterns through GitLab’s analytics use cases, which provides real-time insights into our own development workflows and productivity metrics. Also we will be targeting these use cases for our internal use at first, but it is possible to further extend these to external customers as well.
This covers metrics from Value Stream Analytics, specifically:
- Group Contributions
- Work item aggregations (counts, opened/closed in the given time range, lead times)
- Merge Requests rate
and also metrics from Issue Analytics, such as:
- Opened/closed issues in the given time range, filterable by authors, labels etc.
Requirements
- Offer consistent functionality as available with PostgreSQL
- Improve query performance for interactive dashboards (sub-second to 5 seconds)
- Data freshness within minutes of source changes
- Real-time visibility into work item lifecycle (creation, updates, completion)
Architectural Components

1. Data Ingestion with Siphon
Pattern: Selective table replication from PostgreSQL to ClickHouse with Siphon and NATS streams
- Siphon replicates specific tables data (
issues,merge_requests,issue_assignees,label_links,audit_events) as Logical Replication (LR) Events to dedicated NATS subjects - NATS provides ordering guarantees and durability for change events
- Each replicated table maps to a corresponding ClickHouse table with a mostly identical schema
- ClickHouse consumer reads the LR events from NATS and converts them into applicable rows which are inserted in batches
Note that consumers will ignore the columns from the events that they don’t know about so it is important to keep the clickhouse schema in sync. See this decision for more details.
How to enable replication with Siphon and enable querying from DIP/ClickHouse
Steps for including respective GitLab tables for replication with Siphon and available for querying:
- Recognize the tables that should be optimized for analytical use cases (example issue)
- Define corresponding schema for the tables in ClickHouse (example merge request)
- Add tables configuration to Siphon (example config)
- Define queries by applying the patterns that reflects the usage of the data (example merge request)
- Query the data available on ClickHouse
2. Analytics-Optimized Storage with Materialized Views
Pattern: Transform normalized data into analytics-optimized structure
As the schema in ClickHouse are identical to Postgres version at first, we often need to move the data with materialized views to a more de-normalized and analytics friendly schema.
Materialized View Strategy:
- Raw Data Tables: Direct replicas from PostgreSQL maintain data integrity
- Denormalized Views: Join related tables into analysis-friendly structures, optimized for specific access patterns
- Aggregated Views: Pre-compute common metrics and time-series data
Key thing to note about the materialized views here is that they should be think of as insert triggers which only operate on the incoming block of data on which they are defined.
Specific definitions will depend on the underlying schema but we have compiled few optimizations for improved reference lookups thorough filters like namespaces and projects.
- Populating a column with hierarchical path to improve lookup
- Adding data skipping indexes of columns frequently used for filtering
First of these optimization is improved hierarchical lookup for gitlab data like merge requests, issues, vulnerabilities etc. See this blueprint for more details.
In short, each row is attached with a traversal_path which contains all ancestors for the given namespace record. This improves lookups for specific projects, groups or organizations significantly.
For example traversal_path='1/9970/55154808/95754906/' for Siphon project.
A concrete example showing the SQL definitions and using the filter down to a particular user
CREATE TABLE namespace_traversal_paths(
`id` Int64 DEFAULT 0,
`traversal_path` String DEFAULT '0/',
`version` DateTime64(6, 'UTC') DEFAULT now(),
`deleted` Bool DEFAULT false
)
ENGINE = ReplacingMergeTree(version, deleted)
ORDER BY id
SETTINGS index_granularity = 512; -- optimize single-row value lookups
CREATE MATERIALIZED VIEW namespace_traversal_paths_mv TO namespace_traversal_paths
(
`id` Int64,
`traversal_path` String,
`version` DateTime64(6, 'UTC'),
`deleted` Bool
)
AS SELECT
id,
-- concat organization_id and the traversal_ids array
if(length(traversal_ids) = 0, concat(toString(ifNull(organization_id, 0)), '/'), concat(toString(ifNull(organization_id, 0)), '/', arrayStringConcat(traversal_ids, '/'), '/')) AS traversal_path,
_siphon_replicated_at AS version,
_siphon_deleted AS deleted
FROM gitlab_clickhouse_development.siphon_namespaces
CREATE TABLE IF NOT EXISTS hierarchy_issues
(
traversal_path String,
id Int64,
author_id Nullable(Int64),
...
version DateTime64(6, 'UTC') DEFAULT now(),
deleted Bool DEFAULT FALSE
)
ENGINE = ReplacingMergeTree(version, deleted)
PRIMARY KEY (traversal_path, id);
CREATE MATERIALIZED VIEW hierarchy_issues_mv TO hierarchy_issues
AS WITH
cte AS
(
SELECT *
FROM siphon_issues
),
namespace_paths AS
(
-- look up `traversal_path` values
SELECT
id,
traversal_path
FROM namespace_traversal_paths
WHERE id IN (
SELECT DISTINCT namespace_id
FROM cte
)
)
SELECT
-- handle the case where namespace_id is null
multiIf(cte.namespace_id != 0, namespace_paths.traversal_path, '0/') AS namespace_path,
cte.id Int64,
cte.author_id,
cte.project_id,
...
cte._siphon_replicated_at AS version,
cte._siphon_deleted AS deleted
FROM cte
LEFT JOIN namespace_paths ON namespace_paths.id = cte.namespace_id
SELECT *
FROM hierarchy_issues
WHERE
startsWith(traversal_path, '1/9970/') AND
author_id = 4156052
ORDER BY created_at, id
LIMIT 20;
20 rows in set. Elapsed: 0.034 sec. Processed 780.83 thousand rows
Additional optimization can be done to improve a particular lookup for example: with author_id, by adding data skipping indexes.
ALTER TABLE hierarchy_issues ADD INDEX idx_author_id author_id TYPE set(1000) GRANULARITY 1;
This reduces the number of processed rows.
20 rows in set. Elapsed: 0.022 sec. Processed 421.14 thousand rows
3. Data Consistency with Refresh Mechanisms in Siphon
Pattern: Automated systems ensure data remains current and consistent by using Materialized views and Siphon
Refresh Architecture:
-
Change Detection: Recognize source tables that see updates by using materialized views
-
Dependency Tracking: Manage refresh order based on dependencies in Siphon config and trigger re-inserts on changes
While the replication streams correctly mirrors the updates, it does only for the normalized versions of the configured tables. As we move to de-normalize the tables for analytical purposes, separate efforts have to be made to make sure that designed tables remains consistent with updates. See issue for more details.
This is better illustrated with an example:
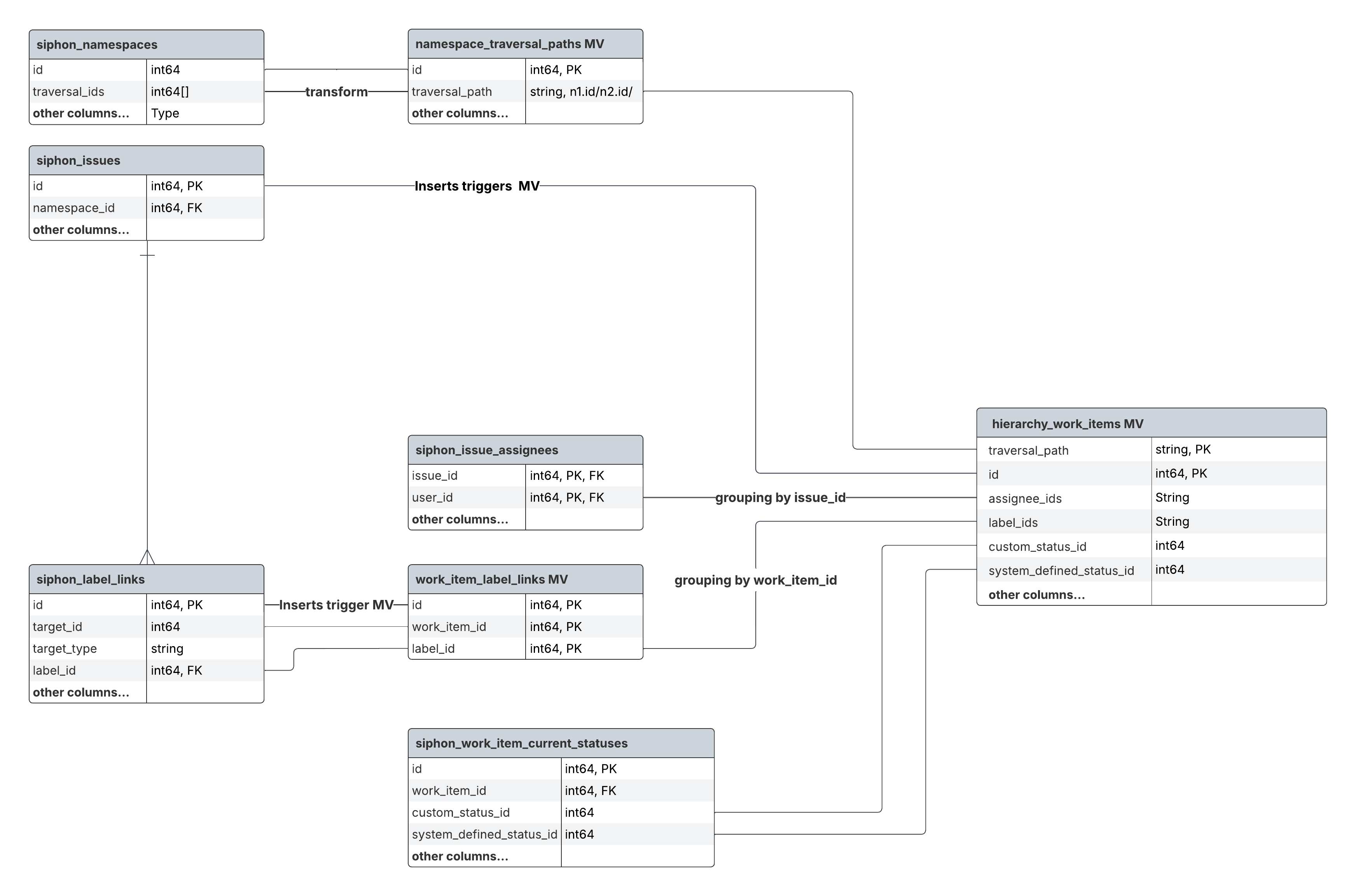
In this example, hierarchy_work_items pulls id by using a MV on siphon_issues and also assignees by JOINing on table siphon_issue_assignees.
However, when a related table like siphon_issue_assignees changes, those changes are not automatically reflected in hierarchy_work_items because the MV can only listens to changes on its source table siphon_issues.
Siphon solves this problem by introducing a mechanism that automatically re-inserts a row in the final table by tracking updates on its dependent table.
It is controlled with configuration:
clickhouse:
host: localhost
...
refresh_on_change:
- stream_identifier: siphon_issue_assignees # which stream to trigger refresh
filters: # optional, filter for specific events
- column: target_type
value: Issue
target_keys: # foreign key value columns within the current stream
- target_id
target_stream_identifier: 'siphon_issues' # which stream to submit the refresh package
source_keys:
- id
How it works
When we receive a change event on the siphon_issue_assignees subject, the consumer responsible for writing the events into ClickHouse:
- Inserts the rows into
siphon_issue_assigneesas usual. - Before acknowledging the message, it emits a logical replication event to the
siphon_issuessubject with a special event type marking it as a refresh event. This only contains the primary key values for the related rows in upstream(siphon_issue_assignees). - The goroutine processing the
issuessubject will picks up this event and after recognising that it is a special event it will: select the latest row fromsiphon_issuesfor each primary key and will re-insert that row with a new version.
As a result, the hierarchy_work_items will see an update on siphon_issue, triggering a fresh JOIN — so assignees will stay in sync with upstream table.
Performance consideration
As adding a refresh_on_change configuration for a stream introduces additional processing on the consumer, it can impact the freshness of the data inserted.
If the stream can work without the need of refreshing, it should be considered.
Concrete details on the performance impact are planned in this issue.
4. Data consistency for tables optimized for access
Pattern: Automated systems ensure data remains consistent for duplicated tables with different ordering keys
All replicated tables in Siphon initially use the ReplacingMergeTree engine with ordering keys that are initially based on how the original table is designed.
It is possible to create a view optimized for a separate access pattern with a different set of ordering key, for e.g.
CREATE TABLE IF NOT EXISTS siphon_label_links
(
id Int64,
label_id Nullable(Int64),
target_id Nullable(Int64),
...
)
ENGINE = ReplacingMergeTree(version, deleted)
PRIMARY KEY id
to optimize access for target_id, this can be duplicated with the help of materialized view as:
CREATE TABLE IF NOT EXISTS work_item_label_links
(
id Int64,
label_id Int64,
target_id Int64,
...
)
ENGINE = ReplacingMergeTree(version, deleted)
PRIMARY KEY (target_id, label_id, id) -- notice the change in keys
Important thing to note here is that row updates are treated as INSERT statements (to work efficiently with ClickHouse and the underlying table engine).
So in cases like above, this can result in data consistency issues when the values in the original table siphon_label_links are updated correctly with the deduplication mechanism of ReplacingMergeTree but the optimized table would end up with copies of both the old and the new row.
Siphon will also have a mechanism to account for this.
How it works
The consumer listening for events on the upstream table will not plainly insert a new row version as is. Instead it will insert 2 rows, one for deleting the old row and one for inserting the new version. This will work as a delete cascade for the row in the downstream table based on materialized view.
5. Query Interface Options
Pattern: Accessing the data with an uniform and performant Query API
Access Methods:
- DIP + GraphQL API: Unified, secure access for application features
- GLQL Integration(To be designed and investigated): Future GitLab Query Language support for advanced analytics
- Direct ClickHouse: For high-performance queries or when the implementation on API is not available
Data Insights Platform(DIP) as a unified abstraction will also allow to query analytical data being stored in ClickHouse.
We will not go into details of the specifics of the query API as there is a separate blueprint regarding it which discusses those in detail.
The API is the recommended way to interact with the data as it allows us to be consistent and unified in way we query the data. It is implemented as a gRPC service included in DIP and is designed to have each RPC method specific to the schema pertaining to it. However, directly accessing ClickHouse inside GitLab application using existing tooling remains available if a corresponding API method is not yet designed or implemented. See this design decision for more details.
Below is an example of how the query API call will looks like:
$ grpcurl -plaintext -d '{
"traversal_path": "1/9970/",
"start_timestamp": "2023-05-01T00:00:00Z",
"end_timestamp": "2023-05-23T00:00:00Z"
}' localhost:8083 gitlab.platform.query.v1.DataInsightsPlatformQueryService/GetWorkItemAggregations
{
"workItems": {
"createdWorkItemsCount": "474816",
"closedWorkItemsCount": "119686",
"leadTimeDuration": "1353s"
}
}
Implementation Phases
Phase 1: Foundation (Current)
- Siphon replication for core tables
- Basic ClickHouse table structures
- Initial materialized views for key metrics
- Documentation and developer tooling
Phase 2: Production Readiness
- Automated refresh mechanisms
- Monitoring and alerting
- Performance optimization
Phase 3: Platform Expansion
- DIP GraphQL integration
- Additional use case implementations
Pros and Cons
Pros:
- Reusable Patterns: Standardized approach reduces development time for new analytical features
- Real-time Performance: Sub-second queries on large datasets through ClickHouse optimization
- Operational Efficiency: Single platform reduces infrastructure complexity
- Scalability: Architecture designed for GitLab.com scale requirements
Cons:
- Complexity: Requires understanding multiple technologies (NATS, ClickHouse, Siphon)
- Data Consistency: Eventually consistent model may not suit all use cases
- Resource Requirements: ClickHouse infrastructure needs significant compute/storage resources
- Learning Curve: Teams need training on new patterns and technologies
ced19998)
