Incident Follow Up Issues
This page documents the process for managing follow-up items from incidents.
Terminology Follow Up …
Incidents are anomalous conditions that result in—or may lead to—service degradation or outages. These events require human intervention to avert disruptions or restore service to operational status. Incidents are always given immediate attention.
The goal of incident management is to organize chaos into swift incident resolution. To that end, incident management provides:
When an incident starts, the incident automation sends a message in the correponding incident announcement channel containing a link to a per-incident Slack channel for text based communication. Within the incident channel, a per-incident Zoom link will be created. Additionally, a GitLab issue will be opened in the Production tracker
Scheduled maintenance that is a C1 should be treated as an undeclared incident.
30-minutes before the maintenance window starts, the Engineering Manager who is responsible for the change should notify the SRE on-call, the Release Managers and the CMOC to inform them that the maintenance is about to begin.
Coordination and communication should take place in the Situation Room Zoom so that it is quick and easy to include other engineers if there is a problem with the maintenance.
If a related incident occurs during the maintenance procedure, the EM should act as the Incident Manager for the duration of the incident.
If a separate unrelated incident occurs during the maintenance procedure, the engineers involved in the scheduled maintenance should vacate the Situation Room Zoom in favour of the active incident.
If brief periods of errors are expected during the scheduled maintenance, this should also be communicated to our users through updates to relevant status pages. In order to not count the duration of the maintenance as downtime towards our Service Level Agreement, we also need to set the maintenance window.
The Incident Lead role must be deliberately set for every incident. If you need help determining the owner of an incident, the EOC can help. The Incident Lead can delegate ownership to another engineer or escalate ownership to the IM at any time. There is only ever one owner of an incident and only the owner of the incident can declare an incident resolved. At anytime the Incident Lead can engage the next role in the hierarchy for support. The Incident Lead role should always be assigned to the current owner.
At GitLab, our incident management framework distinguishes between two important concepts:
Incident Response Roles: These are the functional positions needed during incident response, defined by specific responsibilities and actions, regardless of who fills them. Currently, we have three defined roles: Incident Lead, Incident Responder, and Communications Manager.
Response Teams: These are the specific teams and rotations responsible for staffing these roles. Different response teams may cover different environments (for example, GitLab.com vs. Dedicated) or specialized functions.
Understanding this distinction helps clarify who does what during incidents and ensures proper coordination across our incident management processes.
Clear delineation of responsibilities is important during an incident. Quick resolution requires focus and a clear hierarchy for delegation of tasks. Preventing overlaps and ensuring a proper order of operations is vital to mitigation.
| Role | Description | When Needed |
|---|---|---|
| Incident Lead | The owner of the incident who is responsible for the coordination of the incident response and will drive the incident to resolution. The Incident Lead should always be assigned the role in incident.io. | All incidents require an Incident Lead, which must be set purposefully per-incident. More information on choosing an Incident Lead can be found in the workflow section |
| Incident Responder | Performs technical investigation and mitigation. Responsible for the actual troubleshooting and resolving of the technical issues causing the incident. | All incidents |
| Communications Lead | Disseminates information to stakeholders and customers across multiple media. Manages external communications and status updates. | S1/S2 incidents or when significant communication is required |
We make sure that there are team members available to resolve incidents by maintaining on-call schedules.
When on-call team members are paged, they join an incident and take on one of the incident response roles listed above.
Details of the on-call processes and policies are found in the on-call handbook pages.
Below is a summary of the on-call rotations that support incident resolution:
On-Call rotations notified by automated systems:
| Team | Primary Role | Function | Environment | Who? |
|---|---|---|---|---|
| Engineer On Call (EOC) | Incident Responder | Primarily serves as the initial Incident Responder to automated alerting, and GitLab.com escalations - expectations for the role are in the Handbook for oncall. The checklist for the EOC is in our runbooks. There are runbooks designed to help EOC troubleshoot a broad range of issues - in the case where the runbooks are insufficient, the EOC will escalate by engaging the Incident Manager and CMOC. | GitLab.com | Generally an SRE and can declare an incident. Part of the “GitLab.com Production EOC” on call schedule in incident.io. |
| Incident Manager On Call (IMOC) | Incident Lead | Provides tactical coordination and leadership during complex incidents | GitLab.com | Rotation in incident.io |
In low severity incidents, paged individuals may play multiple roles. For example, in an S4 incident the EOC may both perform the duties of the Incident Lead and Incident Responder. As severity increases, it becomes more important to have single individuals playing these roles; individuals in Tier 2 will need to be paged.
On-Call rotations notified by a human:
| Team | Role(s) | Function | Environment | Who? |
|---|---|---|---|---|
| Communications Manager On Call (CMOC) | Communications Lead | Staffs the Communications Manager role | All environments | Generally a member of the support team at GitLab. |
| Infrastructure Leadership | n/a | Provides escalation support for high severity incidents | All environments | A Staff+ or EM in the Infrastructure, Platform department. |
| Infrastructure Liaison | n/a | Communicates with executive team for S1 incidents | All environments | A grade 10+ member of Infrastructure. |
| Subject Matter Expert (Tier 2 SME) | Incident Responder | Engineers with specific knowledge who can be brought in to support during incidents | GitLab.com / Dedicated | Engineers with specific knowledge |
This table shows which teams typically fulfill which roles during incident response:
| Role | Primary Team(s) | Alternative Team(s) |
|---|---|---|
| Incident Lead | Varies by incident type (see Incident Lead | EOC, IMOC, Product Engineers |
| Incident Responder | EOC | Product Engineers, Other Subject Matter Experts |
| Communications Lead | CMOC | N/A |
The Incident Lead is responsible for ensuring that the incident progresses and is kept updated. This role is not set automatically and should be assigned based on the type of incident. For more guidance on assigning Incident Lead, check out the workflow section. The Incident Lead should feel empowered to engage other parties such as the EOC or IMOC as necessary.
See a more detailed breakdown of incident lead responsibilities.
An Incident Responder is anyone who contributes to the technical investigation and resolution of an incident. While the EOC team typically serves as primary responders, any GitLab team member with relevant expertise may be called upon to assist.
See a more detailed breakdown of incident responder responsibilities
The Communications Lead serves as GitLab’s official voice during serious incidents by managing status page updates, coordinating stakeholder notifications, and ensuring timely public communications about incidents with confirmed significant external customer impact.
For serious incidents that require coordinated communications across multiple channels, the IMOC will rely on the Communications Lead for the duration of the incident.
See a more detailed breakdown of communications lead responsibilities
The Engineer On Call typically serves as the primary Incident Responder and is responsible for the mitigation of impact and resolution to the incident that was declared. The EOC should reach out to the IMOC for support if help is needed or others are needed to aid in the incident investigation.
EOCs should review incident responder responsibilities.
The Incident Manager On Call typically serves as the Incident Lead and is responsible for tactical leadership and coordination during incidents.
IMOCs should review both incident lead responsibilities and communications lead responsibilities since the Incident Lead may also act as the communications lead in many lower severity incidents.
For general information about how shifts are scheduled and common scenarios about what to do when you have PTO or need coverage, see the Incident Manager onboarding documentation
The Infrastructure Leadership is on the escalation path for both Engineer On Call (EOC) and Incident Manager On Call (IMOC). This is not a substitute or replacement for the active IMOC (unless the current IMOC is unavailable).
To page the Infrastructure Leadership directly, run /inc escalate and choose the dotcom leadership escalation from the Oncall Teams drop-down menu
They will be paged in the following circumstances:
When paged, the Infrastructure Leadership will:
To page the Infrastructure Liaison directly, run /inc escalate and choose the Infrastructure Liaison as the impacted service.
During a verified Severity 1 Incident the IMOC will page the Infrastructure Liaison. This is not a substitute or replacement for the active IMOC.
When paged, the Infrastructure Liaison will:
:s1: **Incident on GitLab.com**
**— Summary —**
(include high level summary)
**— Customer Impact —**
(describe the impact to users including which service/access methods and what percentage of users)
**— Current Response —**
(bullet list of actions)
**— Production Issue —**
Main incident: (link to the incident)
Slack Channel: (link to incident slack channel)
~IM-Onboarding::Ready and ~IM-Offboarding issues on the IM onboarding/offboarding board and add these team members to the schedule.#im-general indicating that the schedule has been modified with a link to the MR and a brief overview of who was added or removed.The EOC Coordinator is focused on improving SRE on-call quality of life and setting up processes to keep on-call engineers across the entire company operating at a high level of confidence.
Responsibilities of this role:
The EOC Coordinator will work closely with the Ops Team on core on-call and incident management concerns, and engage other teams across the organization as needed.
Further support is available from the Infrastructure Platforms teams if required. Infrastructure Platforms leadership can be reached via PagerDuty Infrastructure Platforms Escalation (further details available on their team page). Delivery leadership can be reached via PagerDuty. See the Release Management Escalation steps on the Delivery group page.
Admin Notes, leaving a note that contains a link to the incident, and any further notes explaining why the user is being blocked.
If any of the following are true, it would be best to engage an Incident Manager:
Please note that when an incident is upgraded in severity (for example from S3 to S1), incident.io automatically pages the EOC, IMOC, and CMOC.
Occasionally we encounter multiple incidents at the same time. Sometimes a single Incident Manager can cover multiple incidents. This isn’t always possible, especially if there are two simultaneous high-severity incidents with significant activity.
When there are multiple incidents and you decide that additional incident manager help is required, take these actions:
/inc escalate.EOCs are responsible for responding to alerts even on the weekends. Time should not be spent mitigating the incident unless it is a ~severity::1 or ~severity::2. Mitigation for ~severity::3 and ~severity::4 incidents can occur during normal business hours, Monday-Friday. If you have any questions on this please reach out to an Infrastructure Engineering Manager.
If a ~severity::3 and ~severity::4 occurs multiple times and requires weekend work, the multiple incidents should be combined into a single severity::2 incident.
If assistance is needed to determine severity, EOCs and Incident Managers are encouraged to contact Infrastructure Leadership via /inc escalate
A page will be escalated to the Incident Manager (IM) if it is not answered by the Engineer on Call (EOC). This escalation will happen for all alerts that go through incident.io, which includes lower severity alerts. It’s possible that this can happen when there is a large number of pages and the EOC is unable to focus on acknowledging pages. When this occurs, the IM should reach out in Slack in the corresponding incident announcement channel to see if the EOC needs assistance.
Example:
@sre-oncall, I just received an escalation. Are you available to look into LINK_TO_INCIDENT_ESCALATION, or do you need some assistance?
If the EOC does not respond because they are unavailable, you should escalate the incident using the incident.io application, which will alert Infrastructure Engineering leadership.
If during an incident, you need to engage the Incident Responder (EOC), IMOC, or Communications Manager (CMOC), page the person on-call using one of the following methods. This triggers a PagerDuty incident or incident.io Escalation and pages the appropriate person based on the Impacted Service that you select.
/inc escalate command in Slack, select the correct team from the Oncall team drop down menu based on the team below,| Team to Page | Service Name |
|---|---|
| dotcom EOC | dotcom EOC |
| dotcom IMOC | dotcom IMOC |
| CMOC | dotcom CMOC |
If, during an S1 or S2 incident, it is determined that it would be beneficial to have a synchronous conversation with one or more customers a new Zoom meeting should be utilized for that conversation. Typically there are two situations which would lead to this action:
Due to the overhead involved and the risk of detracting from impact mitigation efforts, this communication option should be used sparingly and only when a very clear and distinct need is present.
Implementing a direct customer interaction call for an incident is to be initiated by the current Incident Manager by taking these steps:
/here A second incident manager is required for a customer interaction call for XXX.After learning of the history and current state of the incident the Engineering Communications Lead will initiate and manage the customer interaction through these actions:
GitLab, as well as their Role, CSM Engineering Communications LeadIn some scenarios it may be necessary for most all participants of an incident (including the EOC, other developers, etc.) to work directly with a customer. In this case, the customer interaction Zoom shall be used, NOT the Incident Zoom. This will allow for the conversation (as well as text chat) while still supporting the ability for primary responders to quickly resume internal communications in the Incident Zoom.
Corrective Actions (CAs) are work items that we create as a result of an incident.
Only issues arising out of an incident should receive the label ~"corrective action".
They are designed to prevent the same kind of incident or improve the time to mitigation and as such are part of the Incidence Management cycle.
Corrective Actions must be related to the incident issue to help with downstream analysis.
Corrective Actions issues in the Production Engineering project should be created using the Corrective Action issue template to ensure consistency in format, labels and application/monitoring of service level objectives for completion
Issues that have the ~"corrective action" label will automatically have the ~"infradev" label applied.
This is done so teams these issues are follow the same process we have for development to resolve them in specific time-frames.
For more details see the infradev process.
| Badly worded | Better |
|---|---|
| Fix the issue that caused the outage | (Specific) Handle invalid postal code in user address form input safely |
| Investigate monitoring for this scenario | (Actionable) Add alerting for all cases where this service returns >1% errors |
| Make sure engineer checks that database schema can be parsed before updating | (Bounded) Add automated presubmit check for schema changes |
| Improve architecture to be more reliable | (Time-bounded and specific) Add a redundant node to ensure we no longer have a single point of failure for the service |
Runbooks are available for engineers on call. The project README contains links to checklists for each of the above roles.
In the event of a GitLab.com outage, a mirror of the runbooks repository is available on the Ops instance at https://ops.gitlab.net/gitlab-com/runbooks.
Use the @sre-oncall handle to check who the current EOC is
The current EOC can be contacted via the @sre-oncall handle in Slack, but please only use this handle in the following scenarios.
The EOC will respond as soon as they can to the usage of the @sre-oncall handle in Slack, but depending on circumstances, may not be immediately available. If it is an emergency and you need an immediate response, please see the Reporting an Incident section.
If you are a GitLab team member and would like to report a possible incident related to GitLab.com, follow the instructions below to declare an incident. Please stay online until the EOC has had a chance to come online and engage with you regarding the incident. Thanks for your help!
Type /incident or /inc in GitLab’s Slack and follow the prompts to open an incident issue.
It is always better to err on side of choosing a higher severity, and declaring an incident for a production issue, even if you aren’t sure.
Reporting high severity bugs via this process is the preferred path so that we can make sure we engage the appropriate engineering teams as needed.
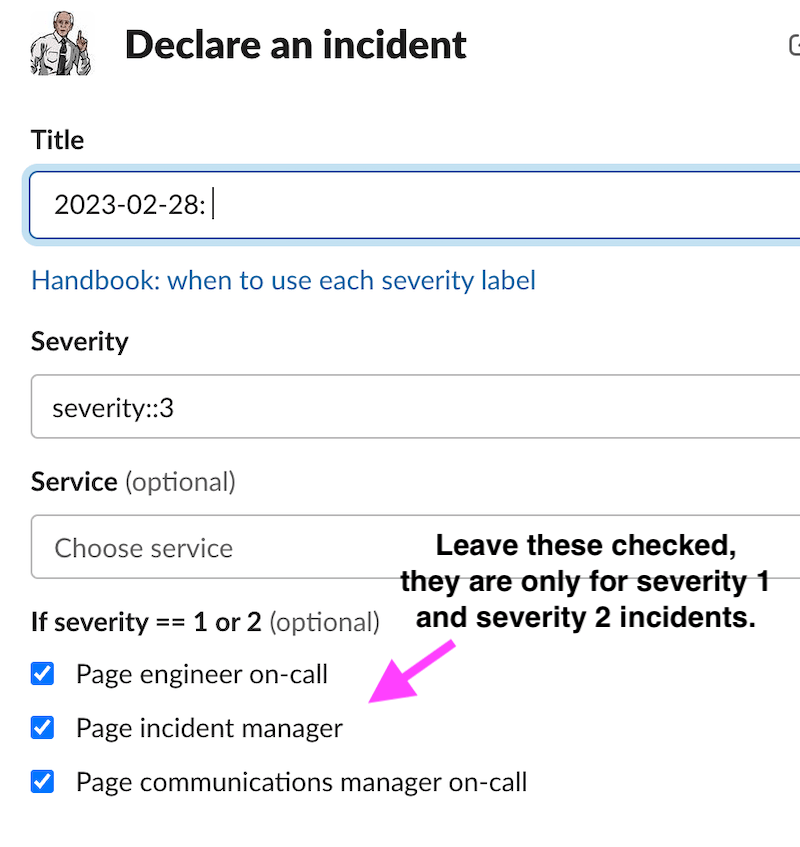 Incident Declaration Slack window
Incident Declaration Slack window
| Field | Description |
|---|---|
| Name | Give a short description of what is happening. If you’d like to, you can leave it blank and change it later |
| Incident Type | Select the appropriate incident type: GitLab.com, Dedicated, SIRT, or Gameday depending on the service affected |
| Initial status | Choose “Active incident” if you’ve confirmed there’s a problem and you’d like to investigate it right away, or “Triage a problem” for initial investigation |
| Severity | If unsure about the severity, but you are seeing a large amount of customer impact, please select S1 or S2. More details here: Incident Severity. The EOC is only paged automatically for S1 or S2. |
| Summary (optional) | Provide your current understanding of what happened in the incident and the impact it had. It’s fine to go into detail here |
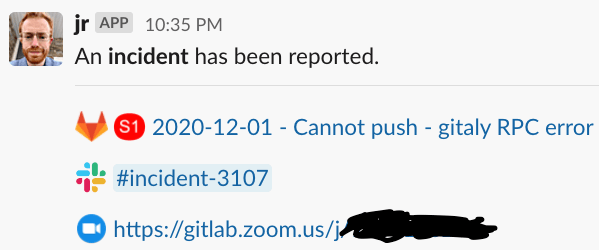
Incident Declaration Results
As well as opening a GitLab incident issue, a dedicated incident Slack channel will be opened. incident.io will post links to all of these resources in the corresponding incident announcement channel. Please join the incident Slack channel, created and linked as a result of the incident declaration, to discuss the incident with the on-call engineer. If you have declared an S3 or S4 and need EOC assistance, please escalate by typing /inc escalate into the Slack channel.
This is a first revision of the definition of Service Disruption (Outage), Partial Service Disruption, and Degraded Performance per the terms on Status.io. Data is based on the graphs from the Key Service Metrics Dashboard
Outage and Degraded Performance incidents occur when:
Degraded as any sustained 5 minute time period where a service is below its documented Apdex SLO or above its documented error ratio SLO.Outage (Status = Disruption) as a 5 minute sustained error rate above the Outage line on the error ratio graph
In both cases of Degraded or Outage, once an event has elapsed the 5 minutes, the Engineer on Call and the Incident Manager should engage the CMOC to help with external communications. All incidents with a total duration of more than 5 minutes should be publicly communicated as quickly as possible (including “blip” incidents), and within 1 hour of the incident occurring.
SLOs are documented in the runbooks/rules
To check if we are Degraded or Disrupted for GitLab.com, we look at these graphs:
A Partial Service Disruption is when only part of the GitLab.com services or infrastructure is experiencing an incident. Examples of partial service disruptions are instances where GitLab.com is operating normally except there are:
In the case of high severity bugs, we prefer that an incident is still created via Reporting an Incident. This will give us an incident issue on which to track the events and response.
In the case of a high severity bug that is in an ongoing, or upcoming deployment please follow the steps to Block a Deployment.
If an incident may be security related, engage the Security Engineer on-call by using /security in Slack. More detail can be found in Engaging the Security Engineer On-Call.
Information is an asset to everyone impacted by an incident. Properly managing the flow of information is critical to minimizing surprise and setting expectations. We aim to keep interested stakeholders apprised of developments in a timely fashion so they can plan appropriately.
This flow is determined by:
Furthermore, avoiding information overload is necessary to keep every stakeholder’s focus.
To that end, we will have:
We have three dedicated incident slack channels where incidents are announced
We manage incident communication using status.io, which updates status.gitlab.com. Incidents in status.io have state and status and are updated by the CMOC.
To create an incident on status.io, you can use /woodhouse incident post-statuspage on Slack.
In some cases, we may choose not to post to status.io, the following are examples where we may skip a post/tweet. In some cases, this helps protect the security of self managed instances until we have released the security update.
Definitions and rules for transitioning state and status are as follows.
| State | Definition |
|---|---|
| Investigating | The incident has just been discovered and there is not yet a clear understanding of the impact or cause. If an incident remains in this state for longer than 30 minutes after the EOC has engaged, the incident should be escalated to the Incident Manager On Call. |
| Active | The incident is in progress and has not yet been mitigated. Note: Incidents should not be left in an Active state once the impact has been mitigated |
| Identified | The cause of the incident is believed to have been identified and a step to mitigate has been planned and agreed upon. |
| Monitoring | The step has been executed and metrics are being watched to ensure that we’re operating at a baseline. If there is a clear understanding of the specific mitigation leading to resolution and high confidence in the fact that the impact will not recur it is preferable to skip this state. |
| Resolved | The impact of the incident has been mitigated and status is again Operational. Once resolved the incident can be marked for review and Corrective Actions can be defined. |
Status can be set independent of state. The only time these must align is when an issues is
| Status | Definition |
|---|---|
| Operational | The default status before an incident is opened and after an incident has been resolved. All systems are operating normally. |
| Degraded Performance | Users are impacted intermittently, but the impact is not observed in metrics, nor reported, to be widespread or systemic. |
| Partial Service Disruption | Users are impacted at a rate that violates our SLO. The Incident Manager On Call must be engaged and monitoring to resolution is required to last longer than 30 minutes. |
| Service Disruption | This is an outage. The Incident Manager On Call must be engaged. |
| Security Issue | A security vulnerability has been declared public and the security team has requested that it be published on the status page. |
Incident severity should be assigned at the beginning of an incident to ensure proper response across the organization. Incident severity should be determined based on the information that is available at the time. Severities can and should be adjusted as more information becomes available. The severity level reflects the maximum impact the incident had and should remain in that level even after the incident was mitigated or resolved. If either the Customer Impact OR the GitLab Impact criteria is met, the Severity for that row should be assigned.
Incident Managers and Engineers On-Call can use the following table as a guide for assigning incident severity.
| Severity | Impact | GitLab Response | Examples |
|---|---|---|---|
| Severity:1 Critical | Customer Impact: Very high impact on users: their customers or business outputs will be impacted OR GitLab Impact: Probable or severe damage to the business |
Immediate all-hands response | - Customer-facing service is down - Confirmed data breach or exposure of red/orange data - Customer data loss - Low-complexity, validated exploit scenario to GitLab’s platform or supply chain. - Critical RCE that is actively exploited or that is unpatched, reachable, and has no exploitability telemetry - Critical vulnerability that has public exposure (press, customers, 0-day by researcher) - External actor controls a highly privileged GitLab service account |
| Severity:2 High | Customer Impact: Significant impact on users: their internal operations will be disrupted OR GitLab Impact: Possible or elevated damage to the business |
Assigned resources, cross-team coordination, and regular stakeholder updates | - Customer-facing service is unavailable for some customers - Core functionality is significantly impacted - Privilege escalation scenarios requiring account compromise or insider-threat motive and knowledge - High severity vulnerability with evidence of exploitation OR high press attention - Suspected unauthorized access into sensitive GitLab systems - Malware detection in GitLab’s cloud infrastructure |
| Severity:3 Medium | Customer Impact: Moderate impact on users: their internal operations may be hampered OR GitLab Impact: Unlikely or mild damage to the business |
Resources are diverted to address beyond normal operating procedures | - Slight performance degradation - Non-critical features not performing optimally - Commodity malware detection in non-critical systems |
| Severity:4 Low | Customer Impact:: Low impact on users: their internal operations may be altered OR GitLab Impact: Minimal damage to the business |
Issue is resolved following standard procedures | - An inconvenience to customers, workaround available - Usable performance degradation - GitLab security policy violations that do not impact red/orange data |
There are four data classification levels defined in GitLab’s Data Classification Standard.
The Incident Manager should exercise caution and their best judgement, in general we prefer to use internal notes instead of marking an entire issue confidential if possible. A couple lines of non-descript log data may not represent a data security concern, but a larger set of log, query, or other data must have more restrictive access. If assistance is required follow the Infrastructure Liaison Escalation process.
The entire incident lifecycle is managed through incident.io. All S1 and S2 incidents require a review, other incidents can also be reviewed as described here.
Incidents are reported and resolved when the degradation has ended and will not likely re-occur.
The Incident Lead is responsible for ensuring that the incident progresses and is kept updated. This role is deliberately assigned after the start of an incident. The Lead should be chosen based on the type of incident, for example:
The incident Timeline is available on the incident in the incident.io web interface by changing “Highlights” to “All Activity” in the Activity section towards the bottom of the page.
Items can be added to the timeline via the :pushpin: (📌) or :star (⭐) emoji reaction to a Slack post within the incident channel. If you react with the :pushpin:, a public comment will
be left on the GitLab incident issue. If you react with a :star:, it will add an internal comment to the GitLab incident issue. Images attached to the Slack message will be added to the incident.io timeline,
but will not be posted to the GitLab issue.
We no longer use only GitLab labels to describe the status of an incident. The source of truth for any incident is incident.io. However, we do have incident.io set some labels based on the state of the incident.
| Label | Workflow State |
|---|---|
~Incident::Active |
Indicates that the incident labeled is active and ongoing. Initial severity is assigned when it is opened. This will be set when the incident is set to Active -> Investigating or Active -> Fixing |
~Incident::Mitigated |
Indicates that the incident has been mitigated. This label is applied if the incident status is set to Active -> Monitoring |
~Incident::Resolved |
Indicates that SRE engagement with the incident has ended and the condition that triggered the alert has been resolved. This will be applied when the incident is in the “Post-incident” or “Closed” stages of the incident lifecycle. |
These labels are added to incident issues as a mechanism to add metadata for the purposes of metrics and tracking.
| Label | Purpose |
|---|---|
~incident (automatically applied) |
Label used for metrics tracking and immediate identification of incident issues. |
~blocks deployments |
Indicates that if the incident is active, it will be a blocker for deployments. This label is set when the custom field “Blocks Deployments” in incident.io is set to yes. It is automatically applied to ~severity::1 and ~severity::2 incidents. |
~blocks feature-flags |
Indicates that while the incident is active, it will be a blocker for changes to feature flags. This label is set when the custom field “Blocks Deployments” in incident.io is set to yes. It is automatically applied to ~severity::1 and ~severity::2 incidents. |
When an incident is created that is a duplicate of an existing incident it is up to the EOC to merge it with the appropriate primary incident. Incidents can only be merged into open incidents, so if necessary you may need to briefly reopen the incident to merge.
GitLab issues are created automatically when a “Follow-up” is created in incident.io. Any GitLab issue can be added as a Follow-up item by pasting the link into the incident Slack channel. Follow-up items are created by default in the incident-follow-ups project and should be moved to the appropriate project after the incident is concluded.
graph TD
A(Incident is declared) --> |initial severity assigned| B(Active->Investigating)
A -.-> |If duplicate| Z(Merged)
B --> |"Fix identified"| C(Active->Fixing)
C --> |"Fix deployed"| D(Active->Monitoring)
D --> |"Incident resolved"| E(Resolved)
E --> |"S1 or S2"| F(Post-Incident Review)
E --> |"S3 or S4"| G(Incident Closed)
A near miss, “near hit”, or “close call” is an unplanned event that has the potential to cause, but does not actually result in an incident.
In the United States, the Aviation Safety Reporting System has been collecting reports of close calls since 1976. Due to near miss observations and other technological improvements, the rate of fatal accidents has dropped about 65 percent. source
Near misses are like a vaccine. They help the company better defend against more serious errors in the future, without harming anyone or anything in the process.
When a near miss occurs, we should treat it in a similar manner to a normal incident.
~Near Miss label.add20892)
